machine learning +
Build a Python AI Chatbot with Memory Using LangChain
Self RAG Explained: Teaching AI to Evaluate Its Own Responses
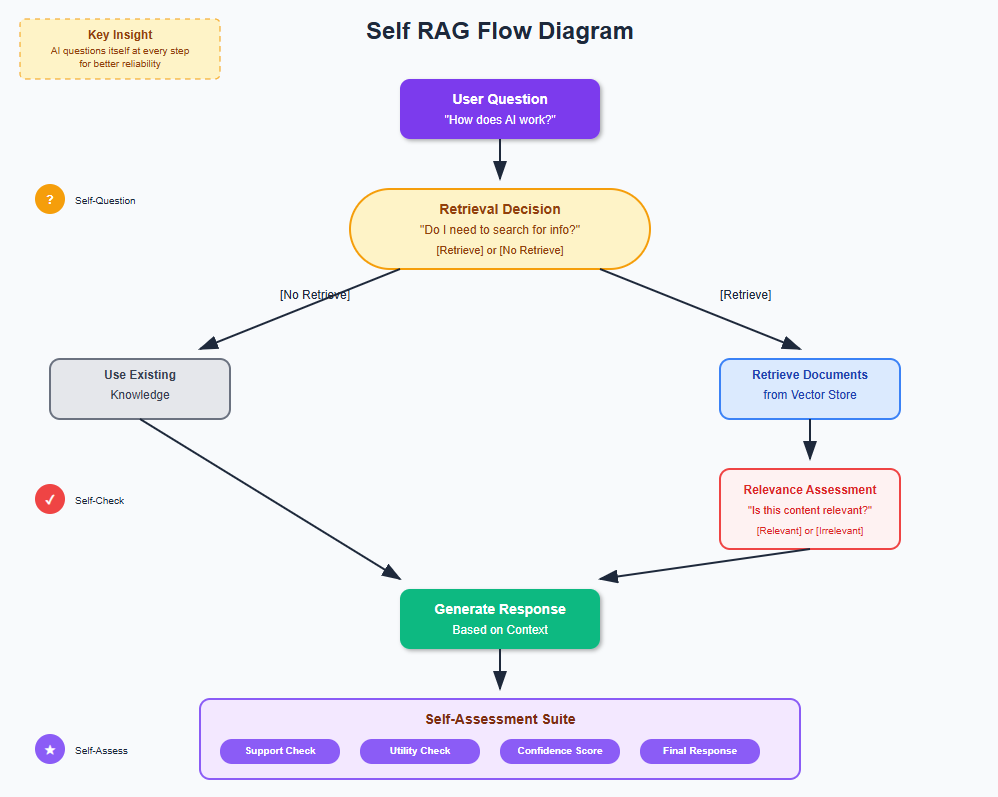
Self RAG (Self-Reflective Retrieval-Augmented Generation) is an advanced AI technique that teaches language models to critique their own performance during the generation process. Instead of blindly retrieving and responding, Self RAG models learn to assess when retrieval is needed, whether retrieved content is relevant, and if their responses are actually supported by the evidence - leading to more accurate and reliable AI responses.
Self RAG (Self-Reflective Retrieval-Augmented Generation) is an advanced AI technique that teaches language models to critique their own performance during the generation process. Instead of blindly retrieving and responding, Self RAG models learn to assess when retrieval is needed, whether retrieved content is relevant, and if their responses are actually supported by the evidence – leading to more accurate and reliable AI responses.
Think about it this way: imagine if every time you answered a question, you automatically asked yourself “Do I actually need to look this up?”, “Is what I found actually relevant?”, and “Does my answer make sense given what I know?”
That’s exactly what Self RAG does for AI systems.
This isn’t just another RAG improvement – it’s a fundamental shift toward self-aware AI that can catch its own mistakes before you even see them. If you’ve ever been frustrated by AI giving you confident-sounding but wrong answers, Self RAG directly addresses that problem.
Let me walk you through exactly how to build this system from scratch.
1. The Problem We’re Solving
Let me paint you a picture of what typically goes wrong with regular RAG systems.
You ask: “What are the health benefits of meditation?”
Regular RAG systems will:
- Always retrieve documents (even if they already know the answer)
- Use whatever they retrieve (even if it’s not relevant)
- Generate an answer (even if it’s not supported by the retrieved content)
- Present it confidently (even if it’s partially wrong)
The result? You get answers that sound authoritative but might be mixing accurate information with irrelevant or unsupported claims.
Self RAG fixes this by adding a layer of self-reflection. The system asks itself:
- “Do I need to retrieve anything, or do I already know this?”
- “Is what I retrieved actually relevant to the question?”
- “Is my answer actually supported by what I found?”
- “Is this response useful to the user?”
This self-questioning leads to much more reliable and trustworthy responses.
2. Setting Up Your Environment
Before we dive into building our Self RAG system, let’s get everything set up. I’ll assume you have Python and VS Code ready.
First, let’s install what we need:
bash
conda create -n self_rag python==3.12
conda activate self_rag
pip install ipykernel
pip install langchain openai faiss-cpu python-dotenv tiktoken pypdf sentence-transformers
Now let’s import everything we’ll use:
python
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.vectorstores import FAISS
from langchain.prompts import PromptTemplate
from langchain.schema import Document
import textwrap
import re
from typing import List, Dict, Tuple
import random
# Load your environment variables
load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv('OPENAI_API_KEY')
Make sure you have a .env file with your OpenAI API key:
python
OPENAI_API_KEY=your_api_key_here
3. Loading and Processing Your Documents
Let’s start by loading a document. Self RAG needs a knowledge base to reflect upon. Without good source material, even the best self-reflection won’t help.
You can download the pdf here
python
# Set the path to our document
document_path = "Robotics.pdf" # Replace with your PDF path
# Load the PDF document
pdf_loader = PyPDFLoader(document_path)
raw_documents = pdf_loader.load()
print(f"Loaded {len(raw_documents)} pages from the PDF")
print(f"First page preview: {raw_documents[0].page_content[:200]}...")
python
Loaded 57 pages from the PDF
First page preview: Comprehensive Guide to Robotics
Table of Contents
1. Introduction to Robotics
2. Historical Development of Robotics
3. Fundamental Concepts and Definitions
4. Types and Classifications of Robots
5. Ro...
Now let’s chunk our documents. Chunking is crucial because we want our AI to retrieve specific, relevant sections rather than entire pages.
python
# Configure our text splitter
chunk_size = 600 # Slightly larger chunks for better context
chunk_overlap = 100 # Overlap to maintain continuity
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
separators=["\n\n", "\n", ". ", " "] # Smart splitting priorities
)
# Split the documents into chunks
document_chunks = text_splitter.split_documents(raw_documents)
print(f"Split {len(raw_documents)} pages into {len(document_chunks)} chunks")
print(f"Average chunk length: {sum(len(chunk.page_content) for chunk in document_chunks) // len(document_chunks)} characters")
python
Split 57 pages into 331 chunks
Average chunk length: 522 characters
The RecursiveCharacterTextSplitter is smart – it tries to split on paragraph breaks first, then sentences, preserving meaning as much as possible. This gives our Self RAG system better context to work with.
4. Creating Your Vector Store
Now we need to convert our text chunks into searchable vectors. Think of this as creating a smart index that can find similar content mathematically.
python
# Initialize OpenAI embeddings
embeddings_model = OpenAIEmbeddings()
# Create vector store using FAISS
print("Creating vector store... This might take a moment.")
vector_store = FAISS.from_documents(
documents=document_chunks,
embedding=embeddings_model
)
print(f"Created vector store with {len(document_chunks)} document chunks")
# Test basic functionality
test_query = "What is machine learning?"
similar_docs = vector_store.similarity_search(test_query, k=3)
print(f"Vector store test successful - found {len(similar_docs)} similar documents")
python
Creating vector store... This might take a moment.
Created vector store with 331 document chunks
Vector store test successful - found 3 similar documents
FAISS (Facebook AI Similarity Search) is like a lightning-fast librarian that can instantly find the most mathematically similar documents to any query. This forms the foundation of our retrieval system.
5. Understanding Self-Reflection Tokens
Before we build our Self RAG system, let’s create the reflection tokens that will guide our AI’s self-assessment.
python
# Define our reflection tokens
REFLECTION_TOKENS = {
'retrieval_decision': ['[Retrieve]', '[No Retrieve]'],
'relevance': ['[Relevant]', '[Irrelevant]'],
'support': ['[Fully Supported]', '[Partially Supported]', '[No Support]'],
'utility': ['[Useful]', '[Not Useful]']
}
print("Self-Reflection Token Categories:")
for category, tokens in REFLECTION_TOKENS.items():
print(f"{category.title()}: {', '.join(tokens)}")
python
Self-Reflection Token Categories:
Retrieval_Decision: [Retrieve], [No Retrieve]
Relevance: [Relevant], [Irrelevant]
Support: [Fully Supported], [Partially Supported], [No Support]
Utility: [Useful], [Not Useful]
These tokens are the heart of Self RAG. They allow the AI to have an internal dialogue about its own performance. Think of them as the AI’s way of taking notes about its own thinking process.
Now let’s create functions to parse these tokens from AI responses:
python
def extract_reflection_tokens(text: str) -> Dict[str, str]:
"""
Extract reflection tokens from AI-generated text
"""
reflections = {}
# Look for each type of reflection token
for category, token_list in REFLECTION_TOKENS.items():
for token in token_list:
if token in text:
reflections[category] = token
break
return reflections
def clean_response_text(text: str) -> str:
"""
Remove reflection tokens from text to get clean response
"""
clean_text = text
for token_list in REFLECTION_TOKENS.values():
for token in token_list:
clean_text = clean_text.replace(token, '')
return clean_text.strip()
# Test the token extraction
test_text = "[Retrieve] I need to look up information about robot sensors. [Relevant] The retrieved information is relevant. [Fully Supported] My answer is backed by evidence."
extracted = extract_reflection_tokens(test_text)
clean_text = clean_response_text(test_text)
print("Extracted tokens:", extracted)
print("Clean text:", clean_text)
python
Extracted tokens: {'retrieval_decision': '[Retrieve]', 'relevance': '[Relevant]', 'support': '[Fully Supported]'}
Clean text: I need to look up information about robot sensors. The retrieved information is relevant. My answer is backed by evidence.
This gives us the tools to understand what our AI is thinking and extract clean responses for the user.
8. Building the Self-Reflection System
Now let’s create the core of our Self RAG system – the ability to make retrieval decisions and assess performance.
python
# Initialize our language model
llm_model = ChatOpenAI(
temperature=0.1, # Low temperature for consistent self-reflection
model_name="gpt-4o-mini",
max_tokens=1500
)
print("Language model initialized for self-reflection")
python
Language model initialized for self-reflection
Let’s create our first self-reflection function – deciding whether retrieval is needed:
python
def should_retrieve_content(question: str) -> Tuple[bool, str]:
"""
Determine if we need to retrieve content to answer the question
"""
decision_prompt = PromptTemplate(
input_variables=["question"],
template="""You are a helpful AI assistant that decides whether you need to search for information to answer a question.
Question: {question}
Think about whether you have enough knowledge to answer this question well, or if you need to search for additional information.
If you need to search, respond with: [Retrieve] followed by your reasoning.
If you don't need to search, respond with: [No Retrieve] followed by your reasoning.
Decision:"""
)
decision_chain = decision_prompt | llm_model
response = decision_chain.invoke({"question": question})
should_retrieve = "[Retrieve]" in response.content
reasoning = clean_response_text(response.content)
return should_retrieve, reasoning
# Test the retrieval decision
test_question = "What are the latest developments in autonomous robot navigation?"
retrieve_decision, reasoning = should_retrieve_content(test_question)
print(f"Question: {test_question}")
print(f"Should retrieve: {retrieve_decision}")
print(f"Reasoning: {reasoning}")
python
Question: What are the latest developments in autonomous robot navigation?
Should retrieve: True
Reasoning: The field of autonomous robot navigation is rapidly evolving, with new developments occurring frequently in areas such as machine learning, sensor technology, and real-time mapping. To provide the most accurate and up-to-date information on the latest advancements, I would need to search for recent articles, research papers, or news updates that reflect the current state of technology and innovations in this area.
This function is crucial because it prevents unnecessary retrievals. If the AI already knows enough to answer well, why waste time searching?
Now let’s create a function to assess whether retrieved content is relevant
python
def assess_content_relevance(question: str, retrieved_content: str) -> Tuple[bool, str]:
"""
Assess whether retrieved content is relevant to the question
"""
relevance_prompt = PromptTemplate(
input_variables=["question", "content"],
template="""You are evaluating whether retrieved content is relevant to answering a question.
Question: {question}
Retrieved Content: {content}
Is this content relevant and helpful for answering the question?
If relevant, respond with: [Relevant] followed by your explanation.
If not relevant, respond with: [Irrelevant] followed by your explanation.
Assessment:"""
)
relevance_chain = relevance_prompt | llm_model
response = relevance_chain.invoke({
"question": question,
"content": retrieved_content
})
is_relevant = "[Relevant]" in response.content
explanation = clean_response_text(response.content)
return is_relevant, explanation
# Test relevance assessment
test_content = "Robot sensors are essential components that enable machines to perceive their environment. Vision systems, proximity sensors, and force sensors work together to provide comprehensive environmental awareness."
relevance_result, explanation = assess_content_relevance(test_question, test_content)
print(f"Content relevance: {relevance_result}")
print(f"Explanation: {explanation}")
python
Content relevance: False
Explanation: The retrieved content discusses robot sensors and their role in environmental perception but does not provide information about the latest developments specifically in autonomous robot navigation. It lacks details on advancements, technologies, or trends that would directly address the question.
This prevents our AI from using irrelevant information, even if it was retrieved. It’s like having a quality filter on the retrieved content.
9. Implementing Support Assessment
One of the most important aspects of Self RAG is assessing whether the AI’s response is actually supported by the retrieved evidence.
python
def assess_response_support(question: str, retrieved_content: str, response: str) -> Tuple[str, str]:
"""
Assess how well the response is supported by retrieved content
"""
support_prompt = PromptTemplate(
input_variables=["question", "content", "response"],
template="""You are evaluating whether a response is supported by the retrieved content.
Question: {question}
Retrieved Content: {content}
Response: {response}
How well is this response supported by the retrieved content?
Choose one:
- [Fully Supported] if the response is completely backed by the content
- [Partially Supported] if some parts are supported but others are not
- [No Support] if the response is not supported by the content
Respond with your choice followed by a detailed explanation.
Assessment:"""
)
support_chain = support_prompt | llm_model
response_obj = support_chain.invoke({
"question": question,
"content": retrieved_content,
"response": response
})
# Extract support level
support_level = None
for token in REFLECTION_TOKENS['support']:
if token in response_obj.content:
support_level = token
break
explanation = clean_response_text(response_obj.content)
return support_level or "[No Support]", explanation
# Test support assessment
test_response = "Robot sensors include vision systems for object recognition, proximity sensors for obstacle avoidance, and force sensors for safe manipulation tasks."
support_level, explanation = assess_response_support(test_question, test_content, test_response)
print(f"Support level: {support_level}")
print(f"Explanation: {explanation}")
python
Support level: [Partially Supported]
Explanation: The response is partially supported by the retrieved content. The retrieved content discusses the role of robot sensors in providing environmental awareness, mentioning vision systems, proximity sensors, and force sensors. The response accurately reflects these components, stating that robot sensors include vision systems for object recognition, proximity sensors for obstacle avoidance, and force sensors for safe manipulation tasks.
However, while the response correctly identifies the types of sensors and their general functions, it does not elaborate on how these sensors contribute specifically to the latest developments in autonomous robot navigation, which is the focus of the original question. Therefore, while the response aligns with the content regarding the types of sensors, it lacks a direct connection to the latest developments in the field, leading to a partial support rating.
This is where Self RAG really shines – it catches responses that sound good but aren’t actually backed by evidence.
10. Creating the Complete Self RAG Pipeline
Now let’s put everything together into a complete Self RAG system
python
def generate_self_rag_response(question: str, vector_store) -> Dict:
"""
Complete Self RAG pipeline with full self-reflection
"""
response_data = {
'question': question,
'reflections': {},
'retrieved_content': None,
'final_response': None,
'confidence_score': 0
}
print(f" Processing question: {question}")
# Step 1: Decide if retrieval is needed
print("\n Step 1: Deciding if retrieval is needed...")
should_retrieve, retrieval_reasoning = should_retrieve_content(question)
response_data['reflections']['retrieval_decision'] = {
'decision': should_retrieve,
'reasoning': retrieval_reasoning
}
retrieved_docs = []
if should_retrieve:
# Step 2: Retrieve relevant documents
print(" Step 2: Retrieving relevant documents...")
retrieved_docs = vector_store.similarity_search(question, k=3)
combined_content = "\n\n".join([doc.page_content for doc in retrieved_docs])
response_data['retrieved_content'] = combined_content
# Step 3: Assess relevance of retrieved content
print(" Step 3: Assessing content relevance...")
is_relevant, relevance_explanation = assess_content_relevance(question, combined_content)
response_data['reflections']['relevance'] = {
'is_relevant': is_relevant,
'explanation': relevance_explanation
}
if not is_relevant:
print(" Retrieved content not relevant. Falling back to general knowledge.")
combined_content = ""
return response_data
# Test the pipeline so far
test_result = generate_self_rag_response("How do the safety integrity levels (SIL) mentioned in the document specifically apply to collaborative robotics systems?", vector_store)
print("\nPipeline test completed")
python
Processing question: How do the safety integrity levels (SIL) mentioned in the document specifically apply to collaborative robotics systems?
Step 1: Deciding if retrieval is needed...
Step 2: Retrieving relevant documents...
Step 3: Assessing content relevance...
Pipeline test completed
Now let’s add the response generation and final assessment
python
def complete_self_rag_response(question: str, vector_store) -> Dict:
"""
Complete Self RAG with response generation and final assessment
"""
# Get initial processing results
response_data = generate_self_rag_response(question, vector_store)
# Step 4: Generate response based on available information
print(" Step 4: Generating response...")
content_context = response_data.get('retrieved_content', '')
generation_prompt = PromptTemplate(
input_variables=["question", "context"],
template="""Answer the following question based on the provided context (if any). Be accurate and honest.
Question: {question}
Context: {context}
If you have sufficient information, provide a comprehensive answer.
If the context is insufficient, acknowledge this and provide what you can based on general knowledge.
Answer:"""
)
generation_chain = generation_prompt | llm_model
response = generation_chain.invoke({
"question": question,
"context": content_context
})
generated_response = response.content.strip()
response_data['final_response'] = generated_response
# Step 5: Assess support and utility
if content_context:
print(" Step 5: Assessing response support...")
support_level, support_explanation = assess_response_support(
question, content_context, generated_response
)
response_data['reflections']['support'] = {
'level': support_level,
'explanation': support_explanation
}
# Step 6: Final utility assessment
print(" Step 6: Assessing response utility...")
utility_assessment = assess_response_utility(question, generated_response)
response_data['reflections']['utility'] = utility_assessment
# Calculate confidence score
response_data['confidence_score'] = calculate_confidence_score(response_data)
return response_data
def assess_response_utility(question: str, response: str) -> Dict:
"""
Assess whether the response is useful to the user
"""
utility_prompt = PromptTemplate(
input_variables=["question", "response"],
template="""Evaluate whether this response is useful for answering the user's question.
Question: {question}
Response: {response}
Is this response useful and helpful?
Respond with [Useful] or [Not Useful] followed by your reasoning.
Assessment:"""
)
utility_chain = utility_prompt | llm_model
result = utility_chain.invoke({
"question": question,
"response": response
})
is_useful = "[Useful]" in result.content
reasoning = clean_response_text(result.content)
return {
'is_useful': is_useful,
'reasoning': reasoning
}
def calculate_confidence_score(response_data: Dict) -> float:
"""
Calculate overall confidence score based on reflections
"""
score = 0.5 # Base score
reflections = response_data['reflections']
# Boost confidence if retrieval decision was appropriate
if 'retrieval_decision' in reflections:
score += 0.1
# Boost if content was relevant
if reflections.get('relevance', {}).get('is_relevant', False):
score += 0.2
# Major boost if response is well supported
support_level = reflections.get('support', {}).get('level', '')
if support_level == '[Fully Supported]':
score += 0.3
elif support_level == '[Partially Supported]':
score += 0.1
# Boost if utility is high
if reflections.get('utility', {}).get('is_useful', False):
score += 0.2
return min(score, 1.0) # Cap at 1.0
# Test the complete system
print(" Testing complete Self RAG system...")
complete_result = complete_self_rag_response(
"How do the safety integrity levels (SIL) mentioned in the document specifically apply to collaborative robotics systems?",
vector_store
)
python
Testing complete Self RAG system...
Processing question: How do the safety integrity levels (SIL) mentioned in the document specifically apply to collaborative robotics systems?
Step 1: Deciding if retrieval is needed...
Step 2: Retrieving relevant documents...
Step 3: Assessing content relevance...
Step 4: Generating response...
Step 5: Assessing response support...
Step 6: Assessing response utility...
11. Testing and Displaying Results
Let’s create a nice way to display our Self RAG results
python
def display_self_rag_results(response_data: Dict):
"""
Display Self RAG results in a clear, readable format
"""
print("=" * 80)
print(" SELF RAG ANALYSIS RESULTS")
print("=" * 80)
print(f"\n QUESTION:")
print(f"{response_data['question']}\n")
print(f" CONFIDENCE SCORE: {response_data['confidence_score']:.2f}")
print(f"\n SELF-REFLECTION PROCESS:")
print("-" * 50)
reflections = response_data['reflections']
# Retrieval decision
if 'retrieval_decision' in reflections:
decision = reflections['retrieval_decision']
print(f" Retrieval Decision: {'Retrieved content' if decision['decision'] else 'Used existing knowledge'}")
print(f" Reasoning: {textwrap.fill(decision['reasoning'], width=70, initial_indent=' ', subsequent_indent=' ')}\n")
# Relevance assessment
if 'relevance' in reflections:
relevance = reflections['relevance']
print(f" Content Relevance: {'Relevant' if relevance['is_relevant'] else 'Not Relevant'}")
print(f" Explanation: {textwrap.fill(relevance['explanation'], width=70, initial_indent=' ', subsequent_indent=' ')}\n")
# Support assessment
if 'support' in reflections:
support = reflections['support']
print(f" Response Support: {support['level']}")
print(f" Analysis: {textwrap.fill(support['explanation'], width=70, initial_indent=' ', subsequent_indent=' ')}\n")
# Utility assessment
if 'utility' in reflections:
utility = reflections['utility']
print(f" Response Utility: {'Useful' if utility['is_useful'] else 'Not Useful'}")
print(f" Assessment: {textwrap.fill(utility['reasoning'], width=70, initial_indent=' ', subsequent_indent=' ')}\n")
print(f" FINAL RESPONSE:")
print("-" * 50)
wrapped_response = textwrap.fill(response_data['final_response'], width=75)
print(wrapped_response)
if response_data.get('retrieved_content'):
print(f"\n RETRIEVED CONTENT USED:")
print("-" * 50)
content_preview = response_data['retrieved_content'][:300] + "..." if len(response_data['retrieved_content']) > 300 else response_data['retrieved_content']
print(textwrap.fill(content_preview, width=75))
# Display our test results
display_self_rag_results(complete_result)
python
================================================================================
SELF RAG ANALYSIS RESULTS
================================================================================
QUESTION:
How do the safety integrity levels (SIL) mentioned in the document specifically apply to collaborative robotics systems?
CONFIDENCE SCORE: 1.00
SELF-REFLECTION PROCESS:
--------------------------------------------------
Retrieval Decision: Retrieved content
Reasoning: The question specifically asks about the application of safety
integrity levels (SIL) to collaborative robotics systems, which is
a specialized topic that may involve specific standards and
practices that I may not have detailed information on. To provide
an accurate and comprehensive answer, I would need to look up the
latest guidelines and standards related to SIL in the context of
collaborative robotics.
Content Relevance: Relevant
Explanation: The retrieved content discusses the concept of safety integrity
levels (SIL) and their importance in ensuring the reliability of
safety systems, which is directly applicable to collaborative
robotics systems. It highlights the need for robust design and
testing procedures to meet the safety requirements associated with
the interaction between humans and robots in shared workspaces.
Additionally, it addresses specific safety features necessary for
collaborative robots, such as force limiting and collision
detection, which are essential for maintaining safety integrity in
these systems. Overall, the content provides a clear connection
between SIL and the safety considerations in collaborative
robotics, making it relevant to the question.
Response Support: [Partially Supported]
Analysis: The response is partially supported by the retrieved content.
Here’s a detailed explanation: 1. **Risk Assessment**: The
response correctly identifies that collaborative robots must assess
risks associated with their operations, particularly in shared
spaces with humans. The retrieved content mentions the need for
systems to detect hazardous conditions and respond appropriately,
which aligns with the idea of risk assessment. 2. **Design
Requirements**: The response accurately states that higher SIL
levels necessitate more rigorous design standards and mentions
specific safety features like force limiting, speed monitoring, and
collision detection. The retrieved content also discusses the
importance of these features in collaborative robotics, supporting
this point. 3. **Testing and Validation**: The response emphasizes
the need for comprehensive testing and validation procedures as
mandated by SIL, which is consistent with the retrieved content's
mention of robust design, testing, and validation procedures for
higher SIL levels. 4. **Dynamic Response**: The response discusses
the need for collaborative robots to dynamically respond to human
presence, which is a critical aspect of safety in shared
workspaces. However, the retrieved content does not explicitly
mention dynamic response or the specifics of modifying robot
behavior based on proximity, making this point less supported. 5.
**Compliance and Standards**: The response highlights the
importance of compliance with industry safety standards, which is a
logical extension of the SIL framework. However, the retrieved
content does not specifically address compliance or standards,
making this point less directly supported. Overall, while the
response captures many key aspects of how SIL applies to
collaborative robotics, it introduces some elements (like dynamic
response and compliance) that are not explicitly covered in the
retrieved content. Therefore, the response is partially supported.
Response Utility: Useful
Assessment: The response effectively addresses the user's question by
explaining how safety integrity levels (SIL) specifically apply to
collaborative robotics systems. It provides a clear and structured
overview of the importance of SIL in this context, covering key
aspects such as risk assessment, design requirements, testing and
validation, dynamic response, and compliance with standards. Each
point elaborates on how SIL contributes to the safety and
reliability of collaborative robots, making the information
relevant and informative for the user.
FINAL RESPONSE:
--------------------------------------------------
The safety integrity levels (SIL) are crucial in the context of
collaborative robotics systems due to the inherent risks associated with
human-robot interaction in shared workspaces. SIL provides a structured
framework for assessing and categorizing the reliability of safety systems
based on the potential consequences of their failure. In collaborative
robotics, where robots and humans operate in close proximity, the
application of SIL is particularly important for several reasons: 1.
**Risk Assessment**: Collaborative robots must be designed to assess the
risks associated with their operations, especially since they share space
with humans. The SIL framework helps in determining the level of safety
required based on the potential severity of injury or harm that could
result from a robot's failure. 2. **Design Requirements**: Higher SIL
levels necessitate more rigorous design standards, which are essential for
collaborative robots. These robots must incorporate advanced safety
features such as force limiting, speed monitoring, and collision detection
to minimize the risk of injury. The SIL framework guides the development of
these features to ensure they meet the necessary reliability standards. 3.
**Testing and Validation**: The SIL framework mandates comprehensive
testing and validation procedures to ensure that safety systems function
correctly and reliably. For collaborative robots, this means that the
safety mechanisms must be thoroughly evaluated under various conditions to
ensure they can effectively prevent accidents during human-robot
interactions. 4. **Dynamic Response**: Collaborative robots must be
capable of dynamically responding to the presence of humans. This includes
modifying their behavior based on proximity and ensuring that their
movements do not pose a threat. The SIL levels help define the necessary
response times and reliability of these safety systems. 5. **Compliance
and Standards**: Adhering to SIL requirements ensures that collaborative
robotics systems comply with industry safety standards and regulations.
This compliance is critical for gaining acceptance in various applications
where human safety is a priority. In summary, the application of safety
integrity levels in collaborative robotics systems is essential for
ensuring that these systems are designed, tested, and validated to operate
safely alongside humans. By following the SIL framework, developers can
create robots that minimize risks and enhance safety in shared work
environments.
RETRIEVED CONTENT USED:
--------------------------------------------------
Functional safety focuses on ensuring that safety-related systems perform
their intended functions correctly and reliably. In robotics, this involves
designing systems that can detect hazardous conditions and respond
appropriately to prevent harm. Safety integrity levels (SIL) provide a
framework fo...
12. Comparing Self RAG vs Traditional RAG
Let’s create a comparison to see the difference between Self RAG and traditional RAG
python
def traditional_rag_response(question: str, vector_store) -> str:
"""
Traditional RAG without self-reflection
"""
# Always retrieve
retrieved_docs = vector_store.similarity_search(question, k=3)
context = "\n\n".join([doc.page_content for doc in retrieved_docs])
# Generate response without reflection
simple_prompt = PromptTemplate(
input_variables=["question", "context"],
template="Answer this question using the provided context:\n\nContext: {context}\n\nQuestion: {question}\n\nAnswer:"
)
chain = simple_prompt | llm_model
response = chain.invoke({"question": question, "context": context})
return response.content
def compare_rag_approaches(question: str, vector_store):
"""
Compare Self RAG with traditional RAG
"""
print(" COMPARISON: Self RAG vs Traditional RAG")
print("=" * 80)
print(f"\nQuestion: {question}\n")
# Traditional RAG
print(" TRADITIONAL RAG:")
print("-" * 40)
traditional_response = traditional_rag_response(question, vector_store)
print(textwrap.fill(traditional_response, width=75))
print("\n" + "=" * 80)
# Self RAG
print(" SELF RAG:")
print("-" * 40)
self_rag_result = complete_self_rag_response(question, vector_store)
print(f"Response: {textwrap.fill(self_rag_result['final_response'], width=75)}")
print(f"Confidence: {self_rag_result['confidence_score']:.2f}")
return traditional_response, self_rag_result
# Run the comparison
comparison_question = "What are the detailed differences between the VAL and RAIL robot programming languages discussed in the document?"
traditional_resp, self_rag_resp = compare_rag_approaches(comparison_question, vector_store)
python
COMPARISON: Self RAG vs Traditional RAG
================================================================================
Question: What are the detailed differences between the VAL and RAIL robot programming languages discussed in the document?
TRADITIONAL RAG:
----------------------------------------
The provided context does not specify detailed differences between the VAL
and RAIL robot programming languages. It mentions that both languages were
developed in the 1980s to facilitate programming complex robot behaviors,
but it does not elaborate on their specific features, syntax, or
functionalities. Therefore, without additional information, we cannot
outline the detailed differences between VAL and RAIL.
================================================================================
SELF RAG:
----------------------------------------
Processing question: What are the detailed differences between the VAL and RAIL robot programming languages discussed in the document?
Step 1: Deciding if retrieval is needed...
Step 2: Retrieving relevant documents...
Step 3: Assessing content relevance...
Retrieved content not relevant. Falling back to general knowledge.
Step 4: Generating response...
Step 5: Assessing response support...
Step 6: Assessing response utility...
Response: The provided context does not include specific details about the
differences between the VAL and RAIL robot programming languages. However,
based on general knowledge, I can provide a comparison of these two
languages. **VAL (Variable Assembly Language)**: 1. **Purpose**: VAL was
developed primarily for programming industrial robots, focusing on motion
control and task execution. 2. **Structure**: It is a high-level language
that allows for structured programming, making it easier to manage complex
robot behaviors. 3. **Features**: VAL includes built-in functions for
motion commands, such as linear and circular interpolation, as well as I/O
operations and basic logic constructs. 4. **Usage**: VAL is often used in
environments where precise control of robotic arms is required, such as in
manufacturing and assembly lines. **RAIL (Robot Artificial Intelligence
Language)**: 1. **Purpose**: RAIL was designed to incorporate more advanced
features, particularly for robots that require higher-level decision-making
and artificial intelligence capabilities. 2. **Structure**: RAIL supports a
more flexible programming model that can handle complex behaviors and
interactions with the environment. 3. **Features**: It includes constructs
for reasoning, learning, and adapting to dynamic environments, making it
suitable for applications beyond traditional industrial settings. 4.
**Usage**: RAIL is often used in research and development of autonomous
robots, particularly in scenarios where robots need to interact with humans
or navigate unstructured environments. **Key Differences**: - **Focus**:
VAL is more focused on motion and control, while RAIL emphasizes decision-
making and adaptability. - **Complexity**: RAIL tends to support more
complex programming paradigms, allowing for the integration of AI
techniques, whereas VAL is more straightforward and geared towards specific
tasks. - **Application Domains**: VAL is typically used in industrial
settings, while RAIL is more applicable to service robotics and research
environments. In summary, while both VAL and RAIL serve the purpose of
programming robots, they cater to different needs and complexities in robot
behavior and control.
Confidence: 0.90
This comparison will show you how Self RAG provides more thoughtful, self-aware responses compared to traditional RAG systems.
Self RAG represents a significant step toward more reliable AI systems. By teaching AI to critique its own performance, we’re building systems that are not just powerful, but also self-aware and trustworthy.
The techniques you’ve learned here form the foundation for building more sophisticated AI applications. Experiment with different reflection strategies, fine-tune your prompts, and adapt the system to your specific use cases.
Remember, the goal isn’t just to get answers – it’s to get answers you can trust.
Free Course
Master Core Python — Your First Step into AI/ML
Build a strong Python foundation with hands-on exercises designed for aspiring Data Scientists and AI/ML Engineers.
Start Free Course →Trusted by 50,000+ learners
Related Course
Master Gen AI — Hands-On
Join 5,000+ students at edu.machinelearningplus.com
Explore Course

