machine learning +
LangGraph RAG Agent: Self-Correcting Retrieval Pipeline
Relevant Segment Extraction (RSE) – Building better Context by assembling contiguous chunks for better RAG Performance
Relevant Segment Extraction (RSE) is a query-time post-processing technique that intelligently combines related text chunks into longer, coherent segments, providing LLMs with better context than individual chunks alone.
Relevant Segment Extraction (RSE) is a query-time post-processing technique that intelligently combines related text chunks into longer, coherent segments, providing LLMs with better context than individual chunks alone. RSE addresses the fundamental limitation of fixed-size chunking by dynamically reconstructing meaningful text segments based on relevance clustering.
Ever asked a question to your RAG chatbot and got an answer that felt incomplete? Like it had the right pieces but couldn’t put them together properly?
This happens because traditional RAG systems retrieve fixed-size chunks. Simple questions might only need one chunk, but complex questions often require information that spans multiple chunks or entire sections.
RSE solves this by finding related chunks and intelligently combining them back into their original coherent segments. Think of it as reassembling puzzle pieces that belong together.
1. Understanding the Chunking Problem
Let me show you why we need RSE in the first place.
Traditional RAG systems break documents into fixed-size chunks – maybe 500 or 1000 characters each. This creates artificial boundaries that can split related information.
Here’s what happens:
Original Document Section:
"Revenue Recognition Policy: Our company recognizes revenue when control of goods or services transfers to customers. This typically occurs upon delivery. For subscription services, we recognize revenue ratably over the subscription period. Special considerations apply to bundled offerings where multiple performance obligations exist."
After Fixed Chunking:
- Chunk 1: “Revenue Recognition Policy: Our company recognizes revenue when control of goods or services transfers to customers. This typically occurs upon delivery.”
Chunk 2: “For subscription services, we recognize revenue ratably over the subscription period. Special considerations apply to bundled offerings…”
You can see the problem. If someone asks “How does the company handle subscription revenue?”, they might only get Chunk 2, missing the broader context from Chunk 1.
RSE fixes this by reassembling these related chunks back into their original coherent segment.
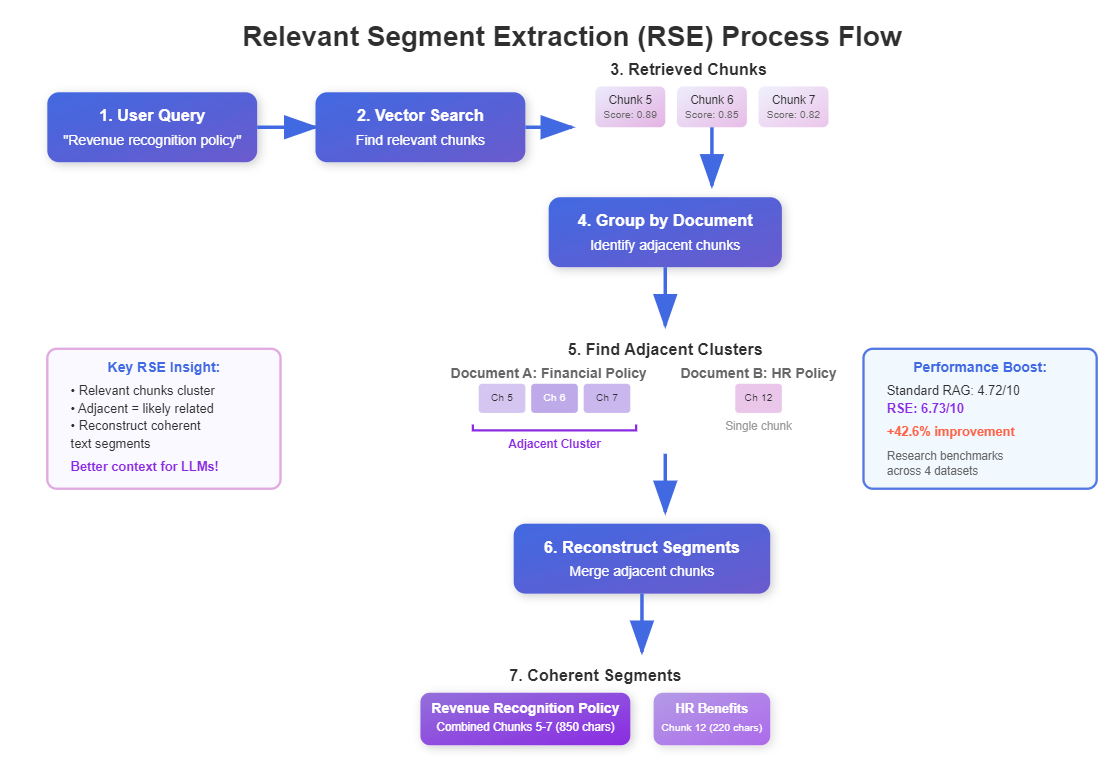
2. How RSE Works – The Core Insight
RSE operates on one key insight: relevant chunks tend to cluster together in their original documents.
If Chunk 15 is highly relevant to your query, there’s a good chance Chunks 14 and 16 are also relevant. RSE exploits this clustering to reconstruct meaningful segments.
The process works in three steps:
- Standard Retrieval: Get the top-k most relevant chunks using traditional methods
- Cluster Analysis: Find which chunks come from the same documents and are near each other
- Segment Reconstruction: Combine adjacent relevant chunks into longer segments
This gives you the best of both worlds – precise retrieval through small chunks, plus rich context through intelligent reconstruction.
3. Setting Up Your Environment
Let’s build an RSE system from scratch. I’ll assume you have Python and VS Code ready.
First, install the required packages:
bash
pip install openai faiss-cpu tiktoken python-dotenv pandas numpy
Now let’s set up our imports and environment:
python
import os
import numpy as np
import pandas as pd
from dotenv import load_dotenv
from openai import OpenAI
import faiss
import tiktoken
from typing import List, Dict, Tuple, Optional
import json
import re
from collections import defaultdict
# Load environment variables
load_dotenv()
client = OpenAI(api_key=os.getenv('OPENAI_API_KEY'))
print("Environment setup complete!")
python
Environment setup complete!
Make sure you have a .env file with your OpenAI API key:
python
OPENAI_API_KEY=your_api_key_here
4. Creating Sample Documents
For this tutorial, let’s create some sample business documents that will show RSE’s power clearly:
python
# Create sample documents that RSE can work with effectively
sample_documents = [
{
"doc_id": "financial_policy",
"title": "Financial Reporting Policy",
"content": """
Revenue Recognition Policy: Our company recognizes revenue when control of goods or services transfers to customers. This typically occurs upon delivery for physical products. For subscription services, we recognize revenue ratably over the subscription period, with monthly recognition for monthly subscriptions and annual recognition spread over twelve months.
Special considerations apply to bundled offerings where multiple performance obligations exist. We allocate transaction price to each performance obligation based on standalone selling prices. This ensures compliance with ASC 606 standards.
Expense Recognition: All expenses are recognized when incurred, following the matching principle. Research and development costs are expensed as incurred unless they meet specific capitalization criteria. Marketing expenses are typically expensed in the period incurred, except for direct response advertising which may be deferred.
Cash Flow Management: We maintain minimum cash reserves of $5M at all times. Free cash flow is calculated as operating cash flow minus capital expenditures. We target a free cash flow margin of at least 15% quarterly.
"""
},
{
"doc_id": "hr_handbook",
"title": "Employee Handbook",
"content": """
Vacation Policy: All full-time employees accrue vacation days based on years of service. New employees receive 15 days annually. After 3 years, this increases to 20 days. After 7 years, employees receive 25 days annually.
Unused vacation days can be carried over up to a maximum of 5 days into the next calendar year. Any excess days are forfeited unless approved by management for special circumstances.
Sick Leave Policy: Employees receive 10 sick days per year, available immediately upon hire. Sick days do not carry over year to year. Medical documentation may be required for absences exceeding 3 consecutive days.
Remote Work Guidelines: Employees may work remotely up to 2 days per week with manager approval. Home office setups must meet security requirements including VPN access and encrypted storage. Regular check-ins are required for remote work days.
"""
},
{
"doc_id": "tech_architecture",
"title": "System Architecture Guide",
"content": """
Database Architecture: Our primary database is PostgreSQL running on AWS RDS with Multi-AZ deployment for high availability. We use read replicas for reporting workloads to reduce load on the primary instance.
Backup procedures run nightly with point-in-time recovery enabled. Full backups are retained for 30 days with weekly backups retained for 1 year. Recovery time objective (RTO) is 4 hours with recovery point objective (RPO) of 1 hour.
API Security: All APIs use OAuth 2.0 authentication with JWT tokens. Rate limiting is implemented at 1000 requests per hour per client. API versioning follows semantic versioning with backward compatibility maintained for at least 12 months.
Monitoring and Alerting: We use DataDog for infrastructure monitoring with alerts configured for CPU usage above 80%, memory usage above 85%, and disk space below 20%. Application performance monitoring tracks response times with alerts for 95th percentile above 2 seconds.
"""
}
]
print(f"Created {len(sample_documents)} sample documents")
print(f"Total content length: {sum(len(doc['content']) for doc in sample_documents)} characters")
python
Created 3 sample documents
Total content length: 3017 characters
This gives us realistic business documents with interconnected information within each document.
5. Building the Chunking System
Now let’s create our chunking system. We need to track where each chunk comes from so RSE can reconstruct segments later:
python
def create_chunks_with_metadata(documents: List[Dict], chunk_size: int = 400, overlap: int = 50) -> List[Dict]:
"""
Create chunks while preserving metadata needed for RSE
"""
all_chunks = []
for doc in documents:
content = doc['content'].strip()
doc_id = doc['doc_id']
# Split content into overlapping chunks
chunks = []
start = 0
chunk_index = 0
while start < len(content):
end = min(start + chunk_size, len(content))
# Try to break at sentence boundary if possible
if end < len(content):
# Look for sentence endings near the boundary
for i in range(end, max(start + chunk_size - 100, start), -1):
if content[i:i+1] in '.!?':
end = i + 1
break
chunk_text = content[start:end].strip()
if chunk_text: # Only add non-empty chunks
chunk_metadata = {
'doc_id': doc_id,
'chunk_index': chunk_index,
'chunk_text': chunk_text,
'start_pos': start,
'end_pos': end,
'doc_title': doc.get('title', '')
}
chunks.append(chunk_metadata)
chunk_index += 1
start = end - overlap if end < len(content) else end
all_chunks.extend(chunks)
return all_chunks
# Create our chunks with metadata
document_chunks = create_chunks_with_metadata(sample_documents)
print(f"Created {len(document_chunks)} chunks total")
print("\nSample chunk structure:")
print(json.dumps(document_chunks[0], indent=2))
python
Created 10 chunks total
Sample chunk structure:
{
"doc_id": "financial_policy",
"chunk_index": 0,
"chunk_text": "Revenue Recognition Policy: Our company recognizes revenue when control of goods or services transfers to customers. This typically occurs upon delivery for physical products. For subscription services, we recognize revenue ratably over the subscription period, with monthly recognition for monthly subscriptions and annual recognition spread over twelve months.",
"start_pos": 0,
"end_pos": 362,
"doc_title": "Financial Reporting Policy"
}
Let’s see one more
python
print(json.dumps(document_chunks[1], indent=2))
python
{
"doc_id": "financial_policy",
"chunk_index": 1,
"chunk_text": "and annual recognition spread over twelve months.\n\nSpecial considerations apply to bundled offerings where multiple performance obligations exist. We allocate transaction price to each performance obligation based on standalone selling prices. This ensures compliance with ASC 606 standards.\n\nExpense Recognition: All expenses are recognized when incurred, following the matching principle.",
"start_pos": 312,
"end_pos": 703,
"doc_title": "Financial Reporting Policy"
}
The key here is that we track each chunk’s position and document. This metadata is crucial for RSE to work.
6. Creating Embeddings and Vector Store
Let’s create embeddings for our chunks and build a simple vector store:
python
def get_embeddings(texts: List[str], model: str = "text-embedding-3-small") -> np.ndarray:
"""
Get embeddings for a list of texts using OpenAI's API
"""
response = client.embeddings.create(
input=texts,
model=model
)
embeddings = np.array([item.embedding for item in response.data])
return embeddings
# Extract just the text for embedding
chunk_texts = [chunk['chunk_text'] for chunk in document_chunks]
print("Creating embeddings...")
embeddings = get_embeddings(chunk_texts)
python
Creating embeddings...
View embeddings sample and shape.
python
print("Embeddings Shape: ", embeddings.shape)
embeddings[:2]
python
Embeddings Shape: (10, 1536)
array([[ 0.02979326, -0.00403853, 0.03639518, ..., 0.00017514,
0.02041032, 0.01686753],
[-0.01146131, -0.02273986, 0.08615562, ..., 0.00112834,
0.00096109, 0.0076561 ]], shape=(2, 1536))
Add the embeddings to the vector store.
python
print(f"Created embeddings with shape: {embeddings.shape}")
# Create FAISS index for fast similarity search
dimension = embeddings.shape[1]
index = faiss.IndexFlatIP(dimension) # Inner product for cosine similarity
index.add(embeddings.astype('float32'))
print(f"Added {index.ntotal} vectors to FAISS index")
python
Created embeddings with shape: (10, 1536)
Added 10 vectors to FAISS index
Now we have our chunks embedded and indexed for fast retrieval.
7. Implementing Basic Retrieval
Before we build RSE, let’s implement standard chunk retrieval to compare against:
python
def search_chunks(query: str, top_k: int = 10) -> List[Dict]:
"""
Search for most relevant chunks using standard retrieval
"""
# Get query embedding
query_embedding = get_embeddings([query])[0]
# Search FAISS index
scores, indices = index.search(
query_embedding.reshape(1, -1).astype('float32'),
top_k
)
# Return chunks with their similarity scores
results = []
for score, idx in zip(scores[0], indices[0]):
if idx < len(document_chunks): # Valid index
chunk_with_score = document_chunks[idx].copy()
chunk_with_score['similarity_score'] = float(score)
results.append(chunk_with_score)
return results
# Test basic retrieval
test_query = "How are subscription revenues handled in accounting?"
basic_results = search_chunks(test_query, top_k=5)
print(f"Query: {test_query}")
print(f"Found {len(basic_results)} relevant chunks:\n")
for i, result in enumerate(basic_results):
print(f"Chunk {i+1} (Score: {result['similarity_score']:.3f}):")
print(f"Document: {result['doc_title']}")
print(f"Text: {result['chunk_text'][:150]}...")
print("-" * 50)
python
Query: How are subscription revenues handled in accounting?
Found 5 relevant chunks:
Chunk 1 (Score: 0.575):
Document: Financial Reporting Policy
Text: Revenue Recognition Policy: Our company recognizes revenue when control of goods or services transfers to customers. This typically occurs upon delive...
--------------------------------------------------
Chunk 2 (Score: 0.449):
Document: Financial Reporting Policy
Text: and annual recognition spread over twelve months.
Special considerations apply to bundled offerings where multiple performance obligations exist. We ...
--------------------------------------------------
Chunk 3 (Score: 0.346):
Document: Financial Reporting Policy
Text: d when incurred, following the matching principle. Research and development costs are expensed as incurred unless they meet specific capitalization cr...
--------------------------------------------------
Chunk 4 (Score: 0.265):
Document: Financial Reporting Policy
Text: aintain minimum cash reserves of $5M at all times. Free cash flow is calculated as operating cash flow minus capital expenditures. We target a free ca...
--------------------------------------------------
Chunk 5 (Score: 0.196):
Document: System Architecture Guide
Text: Database Architecture: Our primary database is PostgreSQL running on AWS RDS with Multi-AZ deployment for high availability. We use read replicas for ...
--------------------------------------------------
This gives us standard RAG retrieval as our baseline.
8. Building the RSE System
Now for the main event – let’s implement Relevant Segment Extraction:
python
def extract_relevant_segments(query: str, top_k: int = 15, max_segments: int = 3) -> List[Dict]:
"""
Main RSE function that finds relevant chunks and reconstructs segments
"""
# Step 1: Get initial relevant chunks
relevant_chunks = search_chunks(query, top_k=top_k)
# Step 2: Group chunks by document
doc_chunks = defaultdict(list)
for chunk in relevant_chunks:
doc_chunks[chunk['doc_id']].append(chunk)
# Step 3: For each document, find continuous segments
segments = []
for doc_id, chunks in doc_chunks.items():
# Sort chunks by their position in the original document
chunks.sort(key=lambda x: x['chunk_index'])
# Find continuous segments
segments.extend(find_continuous_segments(chunks, doc_id))
# Step 4: Score and rank segments
scored_segments = score_segments(segments, query)
# Step 5: Return top segments
return scored_segments[:max_segments]
def find_continuous_segments(chunks: List[Dict], doc_id: str) -> List[Dict]:
"""
Find continuous segments within a document's chunks
"""
if not chunks:
return []
segments = []
current_segment = [chunks[0]]
for i in range(1, len(chunks)):
current_chunk = chunks[i]
last_chunk = current_segment[-1]
# Check if chunks are adjacent (allowing for small gaps)
if current_chunk['chunk_index'] - last_chunk['chunk_index'] <= 2:
current_segment.append(current_chunk)
else:
# Finalize current segment and start new one
if current_segment:
segments.append(create_segment_from_chunks(current_segment))
current_segment = [current_chunk]
# Add the last segment
if current_segment:
segments.append(create_segment_from_chunks(current_segment))
return segments
def create_segment_from_chunks(chunks: List[Dict]) -> Dict:
"""
Combine chunks into a coherent segment
"""
if not chunks:
return {}
# Sort by chunk index to ensure proper order
chunks.sort(key=lambda x: x['chunk_index'])
# Combine text, removing overlap
combined_text = chunks[0]['chunk_text']
for chunk in chunks[1:]:
# Simple overlap removal - in production, you'd want more sophisticated handling
chunk_text = chunk['chunk_text']
# Find overlap with previous text
overlap_found = False
for overlap_len in range(min(100, len(combined_text), len(chunk_text)), 0, -1):
if combined_text[-overlap_len:] in chunk_text[:overlap_len + 50]:
# Found overlap, append remaining text
remaining = chunk_text[overlap_len:]
combined_text += " " + remaining.strip()
overlap_found = True
break
if not overlap_found:
combined_text += " " + chunk_text
segment = {
'doc_id': chunks[0]['doc_id'],
'doc_title': chunks[0]['doc_title'],
'segment_text': combined_text.strip(),
'chunk_count': len(chunks),
'chunk_indices': [c['chunk_index'] for c in chunks],
'avg_similarity': np.mean([c['similarity_score'] for c in chunks])
}
return segment
def score_segments(segments: List[Dict], query: str) -> List[Dict]:
"""
Score segments based on relevance and length
"""
if not segments:
return []
# Get embeddings for all segment texts
segment_texts = [seg['segment_text'] for seg in segments]
segment_embeddings = get_embeddings(segment_texts)
query_embedding = get_embeddings([query])[0]
# Calculate similarity scores
similarities = np.dot(segment_embeddings, query_embedding)
# Add scores to segments
for i, segment in enumerate(segments):
segment['segment_similarity'] = float(similarities[i])
# Bonus for longer segments (more context)
length_bonus = min(len(segment['segment_text']) / 1000, 0.5)
# Final score combines similarity and length
segment['final_score'] = segment['segment_similarity'] + length_bonus
# Sort by final score
return sorted(segments, key=lambda x: x['final_score'], reverse=True)
Let’s run it.
python
# Test RSE
print("Testing Relevant Segment Extraction...")
rse_results = extract_relevant_segments(test_query)
print(f"\nRSE Results for: '{test_query}'")
print("=" * 60)
for i, segment in enumerate(rse_results):
print(f"\nSegment {i+1}:")
print(f"Document: {segment['doc_title']}")
print(f"Chunks combined: {segment['chunk_count']}")
print(f"Similarity score: {segment['segment_similarity']:.3f}")
print(f"Text length: {len(segment['segment_text'])} characters")
print(f"Text preview: {segment['segment_text'][:200]}...")
print("-" * 50)
python
Testing Relevant Segment Extraction...
RSE Results for: 'How are subscription revenues handled in accounting?'
============================================================
Segment 1:
Document: Financial Reporting Policy
Chunks combined: 4
Similarity score: 0.588
Text length: 1156 characters
Text preview: Revenue Recognition Policy: Our company recognizes revenue when control of goods or services transfers to customers. This typically occurs upon delivery for physical products. For subscription service...
--------------------------------------------------
Segment 2:
Document: System Architecture Guide
Chunks combined: 8
Similarity score: 0.212
Text length: 2581 characters
Text preview: Database Architecture: Our primary database is PostgreSQL running on AWS RDS with Multi-AZ deployment for high availability. We use read replicas for reporting workloads to reduce load on the primary ...
--------------------------------------------------
Segment 3:
Document: Employee Handbook
Chunks combined: 3
Similarity score: 0.157
Text length: 867 characters
Text preview: Vacation Policy: All full-time employees accrue vacation days based on years of service. New employees receive 15 days annually. After 3 years, this increases to 20 days. After 7 years, employees rece...
--------------------------------------------------
This is the heart of RSE. We find relevant chunks, group them by document, identify continuous segments, and score them.
9. Comparing RSE vs Standard Retrieval
Let’s build a comparison function to see RSE in action:
python
def compare_retrieval_methods(query: str):
"""
Compare standard chunking vs RSE side by side
"""
print(f"Query: '{query}'")
print("=" * 80)
# Standard retrieval
print("\n🔍 STANDARD CHUNK RETRIEVAL:")
print("-" * 40)
standard_results = search_chunks(query, top_k=3)
for i, chunk in enumerate(standard_results):
print(f"\nChunk {i+1} (Score: {chunk['similarity_score']:.3f}):")
print(f"From: {chunk['doc_title']}")
print(f"Text: {chunk['chunk_text'][:300]}...")
# RSE retrieval
print("\n\n🎯 RELEVANT SEGMENT EXTRACTION:")
print("-" * 40)
rse_results = extract_relevant_segments(query, max_segments=2)
for i, segment in enumerate(rse_results):
print(f"\nSegment {i+1} (Score: {segment['segment_similarity']:.3f}):")
print(f"From: {segment['doc_title']}")
print(f"Combined {segment['chunk_count']} chunks")
print(f"Text: {segment['segment_text'][:400]}...")
python
# Test with different query types
test_queries = [
"How are subscription revenues handled in accounting?",
"What are the backup and recovery procedures?",
"What is our remote work policy and vacation policy?"
]
for query in test_queries:
compare_retrieval_methods(query)
print("\n" + "="*80 + "\n")
python
Query: 'How are subscription revenues handled in accounting?'
================================================================================
🔍 STANDARD CHUNK RETRIEVAL:
----------------------------------------
Chunk 1 (Score: 0.575):
From: Financial Reporting Policy
Text: Revenue Recognition Policy: Our company recognizes revenue when control of goods or services transfers to customers. This typically occurs upon delivery for physical products. For subscription services, we recognize revenue ratably over the subscription period, with monthly recognition for monthly s...
Chunk 2 (Score: 0.449):
From: Financial Reporting Policy
Text: and annual recognition spread over twelve months.
Special considerations apply to bundled offerings where multiple performance obligations exist. We allocate transaction price to each performance obligation based on standalone selling prices. This ensures compliance with ASC 606 standards.
Expense...
Chunk 3 (Score: 0.346):
From: Financial Reporting Policy
Text: d when incurred, following the matching principle. Research and development costs are expensed as incurred unless they meet specific capitalization criteria. Marketing expenses are typically expensed in the period incurred, except for direct response advertising which may be deferred.
Cash Flow Man...
🎯 RELEVANT SEGMENT EXTRACTION:
----------------------------------------
Segment 1 (Score: 0.588):
From: Financial Reporting Policy
Combined 4 chunks
Text: Revenue Recognition Policy: Our company recognizes revenue when control of goods or services transfers to customers. This typically occurs upon delivery for physical products. For subscription services, we recognize revenue ratably over the subscription period, with monthly recognition for monthly subscriptions and annual recognition spread over twelve months. Special considerations apply to bundl...
Segment 2 (Score: 0.212):
From: System Architecture Guide
Combined 8 chunks
Text: Database Architecture: Our primary database is PostgreSQL running on AWS RDS with Multi-AZ deployment for high availability. We use read replicas for reporting workloads to reduce load on the primary instance.
Backup procedures run nightly with point-in-time recovery enabled. Full backups are retained for 30 days with weekly backups retained for 1 year. Recovery time objective (RTO) is 4 hours wi...
================================================================================
Query: 'What are the backup and recovery procedures?'
================================================================================
🔍 STANDARD CHUNK RETRIEVAL:
----------------------------------------
Chunk 1 (Score: 0.449):
From: System Architecture Guide
Text: r 30 days with weekly backups retained for 1 year. Recovery time objective (RTO) is 4 hours with recovery point objective (RPO) of 1 hour.
API Security: All APIs use OAuth 2.0 authentication with JWT tokens. Rate limiting is implemented at 1000 requests per hour per client. API versioning follows s...
Chunk 2 (Score: 0.428):
From: System Architecture Guide
Text: Database Architecture: Our primary database is PostgreSQL running on AWS RDS with Multi-AZ deployment for high availability. We use read replicas for reporting workloads to reduce load on the primary instance.
Backup procedures run nightly with point-in-time recovery enabled. Full backups are retai...
Chunk 3 (Score: 0.308):
From: System Architecture Guide
Text: d compatibility maintained for at least 12 months.
Monitoring and Alerting: We use DataDog for infrastructure monitoring with alerts configured for CPU usage above 80%, memory usage above 85%, and disk space below 20%. Application performance monitoring tracks response times with alerts for 95th pe...
🎯 RELEVANT SEGMENT EXTRACTION:
----------------------------------------
Segment 1 (Score: 0.405):
From: System Architecture Guide
Combined 8 chunks
Text: Database Architecture: Our primary database is PostgreSQL running on AWS RDS with Multi-AZ deployment for high availability. We use read replicas for reporting workloads to reduce load on the primary instance.
Backup procedures run nightly with point-in-time recovery enabled. Full backups are retained for 30 days with weekly backups retained for 1 year. Recovery time objective (RTO) is 4 hours wi...
Segment 2 (Score: 0.226):
From: Financial Reporting Policy
Combined 4 chunks
Text: Revenue Recognition Policy: Our company recognizes revenue when control of goods or services transfers to customers. This typically occurs upon delivery for physical products. For subscription services, we recognize revenue ratably over the subscription period, with monthly recognition for monthly subscriptions and annual recognition spread over twelve months. Special considerations apply to bundl...
================================================================================
Query: 'What is our remote work policy and vacation policy?'
================================================================================
🔍 STANDARD CHUNK RETRIEVAL:
----------------------------------------
Chunk 1 (Score: 0.600):
From: Employee Handbook
Text: equired for absences exceeding 3 consecutive days.
Remote Work Guidelines: Employees may work remotely up to 2 days per week with manager approval. Home office setups must meet security requirements including VPN access and encrypted storage. Regular check-ins are required for remote work days....
Chunk 2 (Score: 0.512):
From: Employee Handbook
Text: Vacation Policy: All full-time employees accrue vacation days based on years of service. New employees receive 15 days annually. After 3 years, this increases to 20 days. After 7 years, employees receive 25 days annually.
Unused vacation days can be carried over up to a maximum of 5 days into the n...
Chunk 3 (Score: 0.402):
From: Employee Handbook
Text: o a maximum of 5 days into the next calendar year. Any excess days are forfeited unless approved by management for special circumstances.
Sick Leave Policy: Employees receive 10 sick days per year, available immediately upon hire. Sick days do not carry over year to year. Medical documentation may ...
🎯 RELEVANT SEGMENT EXTRACTION:
----------------------------------------
Segment 1 (Score: 0.695):
From: Employee Handbook
Combined 3 chunks
Text: Vacation Policy: All full-time employees accrue vacation days based on years of service. New employees receive 15 days annually. After 3 years, this increases to 20 days. After 7 years, employees receive 25 days annually.
Unused vacation days can be carried over up to a maximum of 5 days into the next calendar year. Any excess days are forfeited unless approved by management for special circumsta...
Segment 2 (Score: 0.309):
From: System Architecture Guide
Combined 8 chunks
Text: Database Architecture: Our primary database is PostgreSQL running on AWS RDS with Multi-AZ deployment for high availability. We use read replicas for reporting workloads to reduce load on the primary instance.
Backup procedures run nightly with point-in-time recovery enabled. Full backups are retained for 30 days with weekly backups retained for 1 year. Recovery time objective (RTO) is 4 hours wi...
================================================================================
This comparison will show you how RSE provides more complete, contextual information.
10. Make it as one all encompassing RSE class
Let’s make our RSE system more robust by making it as a class, with all the required methods.
python
class AdvancedRSE:
"""
Advanced RSE system with additional features
"""
def __init__(self, documents: List[Dict], chunk_size: int = 400):
self.documents = documents
self.chunks = create_chunks_with_metadata(documents, chunk_size)
self.embeddings = None
self.index = None
self._build_index()
def _build_index(self):
"""Build the vector index"""
chunk_texts = [chunk['chunk_text'] for chunk in self.chunks]
self.embeddings = get_embeddings(chunk_texts)
dimension = self.embeddings.shape[1]
self.index = faiss.IndexFlatIP(dimension)
self.index.add(self.embeddings.astype('float32'))
def extract_segments(self, query: str,
min_segment_length: int = 200,
max_segment_length: int = 2000,
relevance_threshold: float = 0.3) -> List[Dict]:
"""
Advanced segment extraction with length and relevance controls
"""
# Get initial candidates
candidates = self._get_relevant_chunks(query, top_k=20)
# Filter by relevance threshold
relevant_chunks = [
c for c in candidates
if c['similarity_score'] > relevance_threshold
]
# Group by document and build segments
segments = self._build_segments(relevant_chunks)
# Filter by length constraints
segments = [
s for s in segments
if min_segment_length <= len(s['segment_text']) <= max_segment_length
]
# Score and rank
return self._score_segments(segments, query)
def _get_relevant_chunks(self, query: str, top_k: int) -> List[Dict]:
"""Get relevant chunks using vector search"""
query_embedding = get_embeddings([query])[0]
scores, indices = self.index.search(
query_embedding.reshape(1, -1).astype('float32'), top_k
)
results = []
for score, idx in zip(scores[0], indices[0]):
if idx < len(self.chunks):
chunk = self.chunks[idx].copy()
chunk['similarity_score'] = float(score)
results.append(chunk)
return results
def _build_segments(self, chunks: List[Dict]) -> List[Dict]:
"""Build segments from relevant chunks"""
doc_chunks = defaultdict(list)
for chunk in chunks:
doc_chunks[chunk['doc_id']].append(chunk)
segments = []
for doc_id, doc_chunks_list in doc_chunks.items():
doc_chunks_list.sort(key=lambda x: x['chunk_index'])
segments.extend(self._find_segments_in_document(doc_chunks_list))
return segments
def _find_segments_in_document(self, chunks: List[Dict]) -> List[Dict]:
"""Find continuous segments within a document"""
segments = []
i = 0
while i < len(chunks):
segment_chunks = [chunks[i]]
j = i + 1
# Extend segment while chunks are continuous
while j < len(chunks):
if chunks[j]['chunk_index'] - chunks[j-1]['chunk_index'] <= 2:
segment_chunks.append(chunks[j])
j += 1
else:
break
# Create segment from collected chunks
segment = self._combine_chunks_to_segment(segment_chunks)
segments.append(segment)
i = j
return segments
def _combine_chunks_to_segment(self, chunks: List[Dict]) -> Dict:
"""Combine chunks into a segment with smart text merging"""
combined_text = ""
for i, chunk in enumerate(chunks):
text = chunk['chunk_text'].strip()
if i == 0:
combined_text = text
else:
# Simple overlap detection and removal
words = text.split()[:10] # First 10 words
search_text = " ".join(words)
if search_text in combined_text:
# Skip overlapping part
remaining_text = text[text.find(search_text) + len(search_text):].strip()
if remaining_text:
combined_text += " " + remaining_text
else:
combined_text += " " + text
return {
'doc_id': chunks[0]['doc_id'],
'doc_title': chunks[0]['doc_title'],
'segment_text': combined_text,
'chunk_count': len(chunks),
'avg_similarity': np.mean([c['similarity_score'] for c in chunks])
}
def _score_segments(self, segments: List[Dict], query: str) -> List[Dict]:
"""Score and rank segments"""
if not segments:
return []
segment_texts = [s['segment_text'] for s in segments]
segment_embeddings = get_embeddings(segment_texts)
query_embedding = get_embeddings([query])[0]
similarities = np.dot(segment_embeddings, query_embedding)
for i, segment in enumerate(segments):
segment['segment_similarity'] = float(similarities[i])
# Scoring factors
similarity_score = segment['segment_similarity']
length_score = min(len(segment['segment_text']) / 1000, 0.3)
chunk_diversity = segment['chunk_count'] * 0.1
segment['final_score'] = similarity_score + length_score + chunk_diversity
return sorted(segments, key=lambda x: x['final_score'], reverse=True)
# Test the advanced system
print("Testing Advanced RSE System...")
advanced_rse = AdvancedRSE(sample_documents)
query = "What are the financial policies for revenue and expense recognition?"
results = advanced_rse.extract_segments(query, max_segment_length=1500)
print(f"\nAdvanced RSE Results for: '{query}'")
for i, segment in enumerate(results[:2]):
print(f"\nSegment {i+1}:")
print(f"Document: {segment['doc_title']}")
print(f"Chunks: {segment['chunk_count']}")
print(f"Length: {len(segment['segment_text'])} chars")
print(f"Score: {segment['final_score']:.3f}")
print(f"Text: {segment['segment_text'][:300]}...")
print("-" * 50)
python
Testing Advanced RSE System...
Advanced RSE Results for: 'What are the financial policies for revenue and expense recognition?'
Segment 1:
Document: Financial Reporting Policy
Chunks: 4
Length: 1309 chars
Score: 1.385
Text: Revenue Recognition Policy: Our company recognizes revenue when control of goods or services transfers to customers. This typically occurs upon delivery for physical products. For subscription services, we recognize revenue ratably over the subscription period, with monthly recognition for monthly s...
--------------------------------------------------
This advanced system gives you much more control over segment construction and scoring.
11. Integrate with Q&A Generation
Now let’s show how to use RSE results with a language model for question answering:
python
def answer_with_rse(query: str, rse_system: AdvancedRSE, max_segments: int = 2) -> str:
"""
Generate an answer using RSE-retrieved segments
"""
# Get relevant segments
segments = rse_system.extract_segments(query)[:max_segments]
if not segments:
return "I couldn't find relevant information to answer your question."
# Prepare context from segments
context_parts = []
for i, segment in enumerate(segments):
context_parts.append(f"Context {i+1} (from {segment['doc_title']}):")
context_parts.append(segment['segment_text'])
context_parts.append("")
context = "\n".join(context_parts)
# Create prompt
prompt = f"""Based on the following context, answer the user's question comprehensively.
Context:
{context}
Question: {query}
Answer:"""
# Get response from LLM
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "You are a helpful assistant that answers questions based on provided context. Be comprehensive but concise."},
{"role": "user", "content": prompt}
],
max_tokens=500,
temperature=0
)
return response.choices[0].message.content
# Test question answering with RSE
test_questions = [
"How does the company handle revenue recognition for subscriptions?",
"What backup procedures are in place for our databases?",
"What are the vacation and sick leave policies?"
]
print("Testing Question Answering with RSE:")
print("=" * 60)
for question in test_questions:
answer = answer_with_rse(question, advanced_rse)
print(f"\nQ: {question}")
print(f"A: {answer}")
print("-" * 50)
python
Testing Question Answering with RSE:
============================================================
Q: How does the company handle revenue recognition for subscriptions?
A: The company recognizes revenue for subscription services ratably over the subscription period. This means that for monthly subscriptions, revenue is recognized each month as the service is provided. For annual subscriptions, the revenue is spread evenly over twelve months, ensuring that revenue reflects the delivery of the service throughout the subscription term. This approach aligns with the revenue recognition policy and complies with ASC 606 standards.
--------------------------------------------------
Q: What backup procedures are in place for our databases?
A: The backup procedures for our databases include nightly backups with point-in-time recovery enabled. Full backups are retained for 30 days, while weekly backups are kept for 1 year. This ensures that we have multiple recovery points available in case of data loss or corruption. The recovery time objective (RTO) is set at 4 hours, meaning we aim to restore service within that timeframe, and the recovery point objective (RPO) is 1 hour, indicating that we can tolerate a maximum of 1 hour of data loss in the event of a failure.
--------------------------------------------------
Q: What are the vacation and sick leave policies?
A: The vacation and sick leave policies are as follows:
**Vacation Policy:**
- Full-time employees accrue vacation days based on their years of service:
- New employees receive 15 vacation days annually.
- After 3 years of service, this increases to 20 vacation days annually.
- After 7 years of service, employees receive 25 vacation days annually.
- Unused vacation days can be carried over into the next calendar year, but only up to a maximum of 5 days. Any excess days beyond this limit are forfeited unless special circumstances are approved by management.
**Sick Leave Policy:**
- Employees receive 10 sick days per year, which are available immediately upon hire.
- Sick days do not carry over from year to year.
- If an employee is absent for more than 3 consecutive days, medical documentation may be required.
--------------------------------------------------
This shows how RSE improves the quality of generated answers by providing better context.
12. Evaluation and Performance Metrics
Let’s create some evaluation tools to measure RSE performance:
python
def evaluate_rse_performance():
"""
Simple evaluation comparing RSE vs standard retrieval
"""
# Test queries with expected information needs
test_cases = [
{
"query": "How are subscription revenues recognized?",
"expected_docs": ["financial_policy"],
"needs_multi_chunk": True
},
{
"query": "What is the remote work policy?",
"expected_docs": ["hr_handbook"],
"needs_multi_chunk": False
},
{
"query": "What are our backup and monitoring procedures?",
"expected_docs": ["tech_architecture"],
"needs_multi_chunk": True
}
]
rse_system = AdvancedRSE(sample_documents)
results = {
"standard": {"correct_docs": 0, "total_length": 0, "count": 0},
"rse": {"correct_docs": 0, "total_length": 0, "count": 0}
}
for test_case in test_cases:
query = test_case["query"]
expected_docs = test_case["expected_docs"]
# Test Standard Retrieval
standard_chunks = search_chunks(query, top_k=3)
standard_docs = set(chunk['doc_id'] for chunk in standard_chunks)
standard_text_length = sum(len(chunk['chunk_text']) for chunk in standard_chunks)
# Test RSE
rse_segments = rse_system.extract_segments(query, max_segment_length=1500)[:2]
rse_docs = set(segment['doc_id'] for segment in rse_segments)
rse_text_length = sum(len(segment['segment_text']) for segment in rse_segments)
# Evaluate correctness
if any(doc in standard_docs for doc in expected_docs):
results["standard"]["correct_docs"] += 1
if any(doc in rse_docs for doc in expected_docs):
results["rse"]["correct_docs"] += 1
results["standard"]["total_length"] += standard_text_length
results["standard"]["count"] += 1
results["rse"]["total_length"] += rse_text_length
results["rse"]["count"] += 1
print(f"Query: {query}")
print(f"Standard: {len(standard_chunks)} chunks, {standard_text_length} chars")
print(f"RSE: {len(rse_segments)} segments, {rse_text_length} chars")
print(f"Expected docs: {expected_docs}")
print(f"Standard found: {list(standard_docs)}")
print(f"RSE found: {list(rse_docs)}")
print("-" * 50)
# Print summary
print("\nEVALUATION SUMMARY:")
print(f"Standard Retrieval: {results['standard']['correct_docs']}/{len(test_cases)} correct")
print(f"RSE: {results['rse']['correct_docs']}/{len(test_cases)} correct")
print(f"Average text length - Standard: {results['standard']['total_length'] // len(test_cases)}")
print(f"Average text length - RSE: {results['rse']['total_length'] // len(test_cases)}")
# Run evaluation
evaluate_rse_performance()
python
Query: How are subscription revenues recognized?
Standard: 3 chunks, 1115 chars
RSE: 1 segments, 1117 chars
Expected docs: ['financial_policy']
Standard found: ['financial_policy']
RSE found: ['financial_policy']
--------------------------------------------------
Query: What is the remote work policy?
Standard: 3 chunks, 968 chars
RSE: 1 segments, 925 chars
Expected docs: ['hr_handbook']
Standard found: ['hr_handbook']
RSE found: ['hr_handbook']
--------------------------------------------------
Query: What are our backup and monitoring procedures?
Standard: 3 chunks, 1062 chars
RSE: 1 segments, 1013 chars
Expected docs: ['tech_architecture']
Standard found: ['tech_architecture']
RSE found: ['tech_architecture']
--------------------------------------------------
EVALUATION SUMMARY:
Standard Retrieval: 3/3 correct
RSE: 3/3 correct
Average text length - Standard: 1048
Average text length - RSE: 1018
This gives you a framework for measuring how well RSE performs compared to standard retrieval.
13. Production Considerations
When implementing RSE in production, consider these practical aspects:
- Use async/await for API calls when processing multiple queries
- Cache embeddings to avoid recomputation
- Use faster vector databases like Pinecone or Weaviate
- Implement chunk-level caching for frequently accessed segments
- Use batch processing for embedding generation
- Consider using smaller embedding models for speed vs accuracy tradeoffs
- Implement segment result caching for common queries
python
class ProductionRSE:
"""
Production-ready RSE implementation with performance optimizations
"""
def __init__(self, chunk_size: int = 400, max_segment_length: int = 2000):
self.chunk_size = chunk_size
self.max_segment_length = max_segment_length
self.chunk_store = {} # Fast chunk lookup by doc_id + chunk_index
def add_document(self, doc_id: str, content: str, metadata: Dict = None):
"""
Add a document to the RSE system
"""
chunks = self._create_chunks(doc_id, content, metadata or {})
# Store chunks for fast lookup
for chunk in chunks:
key = f"{doc_id}_{chunk['chunk_index']}"
self.chunk_store[key] = chunk
return len(chunks)
def _create_chunks(self, doc_id: str, content: str, metadata: Dict) -> List[Dict]:
"""
Create chunks with production-quality text splitting
"""
chunks = []
# Use sentence boundaries for better chunking
sentences = re.split(r'(?<=[.!?])\s+', content)
current_chunk = ""
chunk_index = 0
for sentence in sentences:
if len(current_chunk) + len(sentence) <= self.chunk_size:
current_chunk += " " + sentence if current_chunk else sentence
else:
if current_chunk:
chunks.append({
'doc_id': doc_id,
'chunk_index': chunk_index,
'chunk_text': current_chunk.strip(),
'metadata': metadata
})
chunk_index += 1
current_chunk = sentence
# Add final chunk
if current_chunk:
chunks.append({
'doc_id': doc_id,
'chunk_index': chunk_index,
'chunk_text': current_chunk.strip(),
'metadata': metadata
})
return chunks
def get_segment_by_range(self, doc_id: str, start_chunk: int, end_chunk: int) -> Optional[str]:
"""
Efficiently reconstruct a segment from chunk range
"""
segment_parts = []
for chunk_idx in range(start_chunk, end_chunk + 1):
key = f"{doc_id}_{chunk_idx}"
if key in self.chunk_store:
segment_parts.append(self.chunk_store[key]['chunk_text'])
if not segment_parts:
return None
# Smart text merging to remove overlaps
merged_text = segment_parts[0]
for next_text in segment_parts[1:]:
# Find potential overlap
overlap_found = False
for overlap_len in range(min(50, len(merged_text), len(next_text)), 10, -1):
if merged_text[-overlap_len:].strip() in next_text[:overlap_len + 20]:
merged_text += " " + next_text[overlap_len:].strip()
overlap_found = True
break
if not overlap_found:
merged_text += " " + next_text
return merged_text.strip()
# Example of production optimization
def optimize_rse_for_scale():
"""
Tips for scaling RSE in production
"""
optimizations = [
"Use async/await for API calls when processing multiple queries",
"Cache embeddings to avoid recomputation",
"Use faster vector databases like Pinecone or Weaviate",
"Implement chunk-level caching for frequently accessed segments",
"Use batch processing for embedding generation",
"Consider using smaller embedding models for speed vs accuracy tradeoffs",
"Implement segment result caching for common queries"
]
print("Production RSE Optimizations:")
for i, tip in enumerate(optimizations, 1):
print(f"{i}. {tip}")
optimize_rse_for_scale()
python
Production RSE Optimizations:
1. Use async/await for API calls when processing multiple queries
2. Cache embeddings to avoid recomputation
3. Use faster vector databases like Pinecone or Weaviate
4. Implement chunk-level caching for frequently accessed segments
5. Use batch processing for embedding generation
6. Consider using smaller embedding models for speed vs accuracy tradeoffs
7. Implement segment result caching for common queries
14. Key Takeaways and Best Practices
RSE is powerful, but here are the key points to remember:
When RSE Works Best:
– Complex questions that need multi-paragraph context
– Documents with logical structure (sections, chapters)
– Queries where related information is scattered across adjacent chunks
RSE Implementation Tips:
1. Tune your chunk size: Smaller chunks give RSE more flexibility
2. Set relevance thresholds: Don’t combine chunks that aren’t truly related
3. Limit segment length: Very long segments can confuse LLMs
4. Monitor performance: RSE adds computation cost – measure the benefit
Common Pitfalls:
– Avoid Combining unrelated chunks just because they’re adjacent
– Making segments too long for your LLM’s context window
– Not handling text overlaps properly during reconstruction. This can be tricky to handle for the LLMs.
RSE represents a significant improvement over basic chunking for many RAG use cases. It bridges the gap between the precision of small chunks and the context richness of large segments. The key insight is that the relevant information in a document tend to cluster together.
By leveraging this insight, RSE helps your RAG system provide more complete, contextual answers.
Try implementing RSE with your own documents and see how it improves your question-answering quality. Start with the basic version, then add advanced features as you see the benefits.
Remember: the best RAG system is one that’s tuned for your specific use case and data. RSE is a tool in your toolkit – use it when it makes sense, and combine it with other techniques for maximum effectiveness.
Free Course
Master Core Python — Your First Step into AI/ML
Build a strong Python foundation with hands-on exercises designed for aspiring Data Scientists and AI/ML Engineers.
Start Free Course →Trusted by 50,000+ learners
Related Course
Master Gen AI — Hands-On
Join 5,000+ students at edu.machinelearningplus.com
Explore Course

