machine learning +
Build a Python AI Chatbot with Memory Using LangChain
RAPTOR RAG Explained: Building Hierarchical Retrieval for Smarter AI Answers
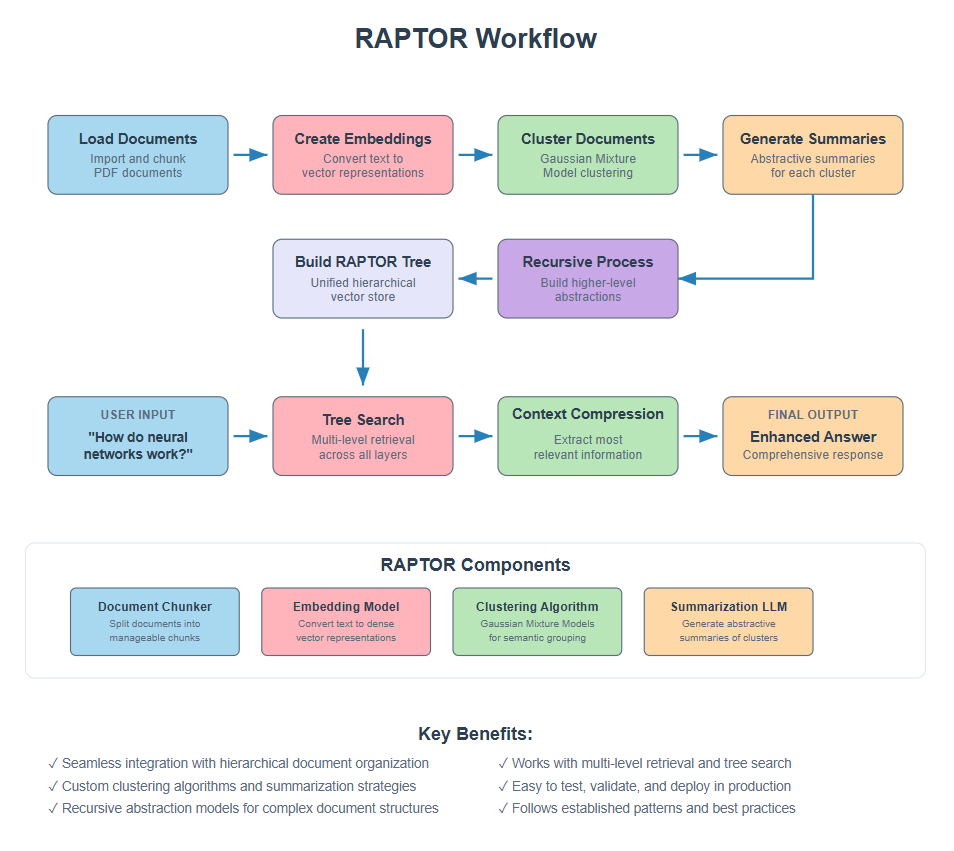
RAPTOR (Recursive Abstractive Processing for Tree-Organized Retrieval) is an advanced RAG technique that creates hierarchical tree structures from your documents, allowing you to retrieve information at different levels of detail and abstraction. Unlike traditional RAG that searches through flat document chunks, RAPTOR builds a multi-level tree where each layer contains increasingly abstract summaries, making it incredibly powerful for complex queries that need both specific details and high-level insights._
RAPTOR (Recursive Abstractive Processing for Tree-Organized Retrieval) is an advanced RAG technique that creates hierarchical tree structures from your documents, allowing you to retrieve information at different levels of detail and abstraction. Unlike traditional RAG that searches through flat document chunks, RAPTOR builds a multi-level tree where each layer contains increasingly abstract summaries, making it incredibly powerful for complex queries that need both specific details and high-level insights.
Imagine you’re working with a massive technical manual. Traditional RAG might find you the exact paragraph about a specific function, but what if you need to understand how that function fits into the bigger picture?
That’s where RAPTOR comes in.
I’ll walk you through building this system step by step, and by the end, you’ll understand why this approach is revolutionizing how we handle complex document retrieval.
1. The Problem We’re Solving
Let me paint you a picture. You have a large collection of documents about machine learning. A user asks: “How do neural networks compare to traditional algorithms in terms of scalability and performance?”
Traditional RAG faces a challenge here.
It might find specific chunks about neural networks and others about traditional algorithms, but it struggles to provide the comparative analysis and high-level insights the user needs.
Here’s what typically happens:
- Traditional RAG finds isolated chunks of information
- No connection between related concepts across different sections
- Misses the “big picture” context that ties everything together
- Can’t provide multi-level insights (both detailed and abstract)
RAPTOR solves this by creating a tree structure
2. How RAPTOR Works
Researchers Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D. Manning introduced RAPTOR in their 2024 paper “RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval.” Their innovation was building knowledge pyramids through recursive clustering and summarization.
RAPTOR works like building a knowledge pyramid: first clustering similar document chunks, then creating summaries for each cluster, then treating those summaries as new documents and repeating the process.
Each level gives you a different perspective – specific details at the bottom, increasingly abstract insights at higher levels.
The result is a system that can answer both detailed factual questions and high-level thematic queries by navigating through different abstraction levels of your knowledge base.
3. Setting Up Your Environment
Before we dive into the code, let’s get everything set up. I’ll assume you have Python and VS Code ready to go.
First, let’s install the packages we need:
bash
conda create -p rag python==3.12
conda activate rag
pip install ipykernel
pip install langchain openai faiss-cpu python-dotenv tiktoken pypdf
pip install scikit-learn numpy pandas
Now let’s import everything:
python
import numpy as np
import pandas as pd
from typing import List, Dict, Any
import os
from dotenv import load_dotenv
# NirDiamant's key imports - these are essential for his methodology
from sklearn.mixture import GaussianMixture # For clustering (better than K-means)
from langchain.chains.llm import LLMChain
from langchain.vectorstores import FAISS
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain.prompts import ChatPromptTemplate
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
from langchain.schema import AIMessage, Document
from langchain_community.document_loaders import PyPDFLoader
import matplotlib.pyplot as plt
# Load environment variables
load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv('OPENAI_API_KEY')
print("All packages imported successfully!")
python
All packages imported successfully!
Quick note: Make sure you have a .env file with your OpenAI API key. It should look like this:
python
OPENAI_API_KEY=your_api_key_here
4. Loading and Processing Your Documents
Let’s start with loading your document. I will be using a PDF on Artificial Intelligence and Machine Learning.
You can download the pdf here
python
# Load your AI/ML document
document_path = "Artificial Intelligence.pdf" # Replace with your document path
# Load the PDF and extract text from each page
loader = PyPDFLoader(document_path)
documents = loader.load()
texts = [doc.page_content for doc in documents]
print(f"Loaded {len(documents)} pages from the AI/ML document")
print(f"First page preview:")
print("-" * 50)
print(texts[0][:400] + "...")
python
Loaded 14 pages from the AI/ML document
First page preview:
--------------------------------------------------
Artificial Intelligence and Machine Learning: Fundamentals,
Applications, and Future Directions
Introduction to Artificial Intelligence
Artificial Intelligence represents one of the most transformative technological developments of the
modern era. Defined as the simulation of human intelligence processes by machines, AI
encompasses a broad spectrum of capabilities including learning, reasoning, pr...
5. Helper Functions
Now let’s create helper functions to avoid repeating the same code multiple times.
Since the same steps need to be implemented across different layers, these functions help reduce redundancy and minimize code fatigue.
Each function has a single, clear purpose, making our code easier to understand, debug, and maintain.
python
# Initialize AI components
embeddings = OpenAIEmbeddings()
llm = ChatOpenAI(model_name="gpt-4o-mini")
def create_embeddings_batch(texts_list, embeddings_model):
"""Convert texts to embeddings - unified function to avoid duplication."""
print(f" Creating embeddings for {len(texts_list)} texts...")
all_embeddings = []
for text in texts_list:
# Handle different text formats
text_content = text.content if hasattr(text, 'content') else str(text)
embedding = embeddings_model.embed_documents([text_content])
all_embeddings.extend(embedding) # This adds the embedding vector to the list
print(f" Created {len(all_embeddings)} embeddings")
return all_embeddings
We’ll need to create embeddings at every tree level (Level 0, Level 1, Level 2, etc.).
This function converts any list of texts into numerical embeddings (vectors) that capture semantic meaning.
It also handles different text formats consistently.
python
def cluster_with_gmm(embeddings_array, n_clusters):
"""Cluster embeddings using Gaussian Mixture Models."""
# Ensure we don't try to create more clusters than data points
n_clusters = min(n_clusters, len(embeddings_array))
if n_clusters < 2:
return np.zeros(len(embeddings_array)) # Single cluster
print(f" Clustering into {n_clusters} groups...")
gm = GaussianMixture(n_components=n_clusters, random_state=42)
return gm.fit_predict(embeddings_array)
This function groups similar documents together using Gaussian Mixture Models (GMM), which can handle overlapping concepts better.
The clustering is essential for RAPTOR’s hierarchical structure – it determines which documents get summarized together at each level, creating meaningful thematic groups that preserve related information.
python
def generate_summaries_for_clusters(texts, cluster_labels, level_number, llm_model):
"""Generate summaries for each cluster."""
print(f" Generating summaries for Level {level_number}...")
summaries = []
metadata_list = []
unique_clusters = np.unique(cluster_labels)
for cluster_id in unique_clusters:
# Get texts in this cluster
cluster_mask = cluster_labels == cluster_id
cluster_texts = [texts[i] for i in range(len(texts)) if cluster_mask[i]]
# Combine and summarize
combined_text = "\n\n".join(cluster_texts)
prompt = ChatPromptTemplate.from_template(
"Summarize the following content concisely, focusing on key concepts and relationships:\n\n{text}"
)
chain = prompt | llm_model
result = chain.invoke({"text": combined_text[:4000]}) # Limit context
summary = result.content if hasattr(result, 'content') else str(result)
summaries.append(summary)
# Create metadata
metadata = {
"level": level_number,
"cluster_id": int(cluster_id),
"source_docs": len(cluster_texts),
"id": f"summary_L{level_number}_C{cluster_id}"
}
metadata_list.append(metadata)
return summaries, metadata_list
This is the heart of RAPTOR’s hierarchical abstraction. For each cluster of similar documents, it combines their content and creates a concise summary that captures key concepts and relationships.
The function carefully tracks metadata (which level, which cluster, how many source documents) to maintain the tree structure’s traceability.
python
def create_dataframe_for_level(texts, embeddings_list, metadata_list, cluster_labels=None):
"""Create organized DataFrame for each tree level."""
df = pd.DataFrame({
'text': texts,
'embedding': embeddings_list,
'metadata': metadata_list
})
if cluster_labels is not None:
df['cluster'] = cluster_labels
return df
This function creates a standardized data structure for each tree level, organizing texts, their embeddings, and metadata into a clean pandas DataFrame.
This consistent structure is vital for RAPTOR because it allows us to easily navigate between tree levels, track document relationships, and build the unified vectorstore.
6. Building Level 0 (Foundation Layer)
Level 0 contains our original documents – the raw material from which we’ll build abstractions. We need to convert these documents into embeddings and organize them with metadata.
python
# Build Level 0 - Original documents
print(" Building Level 0 (Original Documents)...")
# Create embeddings for all original texts
embeddings_list = create_embeddings_batch(texts, embeddings)
# Create metadata for original documents
level_0_metadata = []
for i, text in enumerate(texts):
metadata = {
"level": 0,
"origin": "original",
"id": f"doc_{i}",
"text_length": len(text)
}
level_0_metadata.append(metadata)
# Create Level 0 DataFrame
level_0_df = create_dataframe_for_level(
texts,
embeddings_list, # Use the list directly
level_0_metadata
)
print(f" Level 0 created with {len(level_0_df)} documents")
print(f" Sample metadata: {level_0_df['metadata'].iloc[0]}")
# Store in our tree structure
tree_levels = {0: level_0_df}
# Convert to numpy array for clustering (we need numpy array for GMM)
embeddings_array = np.array(embeddings_list)
python
Building Level 0 (Original Documents)...
Creating embeddings for 14 texts...
Created 14 embeddings
Level 0 created with 14 documents
Sample metadata: {'level': 0, 'origin': 'original', 'id': 'doc_0', 'text_length': 2785}
This Level 0 contains the most specific information and serves as the base for all higher abstraction levels.
7. Building Level 1 (First Abstraction Layer)
Now we need to find patterns and group similar documents together. By clustering Level 0 documents, we identify themes and relationships.
python
# Cluster Level 0 documents
optimal_clusters = min(8, max(2, len(texts) // 3)) # Smart cluster sizing
cluster_labels = cluster_with_gmm(embeddings_array, optimal_clusters)
# Add clusters to Level 0
level_0_df['cluster'] = cluster_labels
print(" Clustering Results:")
for cluster_id in np.unique(cluster_labels):
count = sum(cluster_labels == cluster_id)
print(f" Cluster {cluster_id}: {count} documents")
# Generate Level 1 summaries
level_1_summaries, level_1_metadata = generate_summaries_for_clusters(
texts, cluster_labels, level_number=1, llm_model=llm
)
# Create embeddings for summaries
level_1_embeddings = create_embeddings_batch(level_1_summaries, embeddings)
# Create Level 1 DataFrame
level_1_df = create_dataframe_for_level(
level_1_summaries,
level_1_embeddings, # Remove list() conversion since it's already a list
level_1_metadata
)
# Add to tree
tree_levels[1] = level_1_df
print(f" Level 1 created with {len(level_1_df)} summaries")
print(f" Sample summary: {level_1_summaries[0][:150]}...")
python
Clustering into 4 groups...
Clustering Results:
Cluster 0: 2 documents
Cluster 1: 6 documents
Cluster 2: 4 documents
Cluster 3: 2 documents
Generating summaries for Level 1...
Creating embeddings for 4 texts...
Created 4 embeddings
Level 1 created with 4 summaries
Sample summary: The content discusses key advancements in machine learning, particularly in the areas of deep networks and reinforcement learning (RL). Architectural ...
We clustered original documents by semantic similarity and created summaries for each cluster.
This produced Level 1 – our first abstraction layer with fewer, more thematic summaries that capture relationships between related documents.
8. Build Higher Levels (Recursive Abstraction)
If Level 1 still has many summaries, we can cluster and summarize them again to create even higher-level abstractions.
Think of it as creating increasingly zoomed-out views of your content – from detailed paragraphs to chapter summaries to book overviews.
python
# Continue building levels until we have few enough summaries
current_level = 1
current_texts = level_1_summaries
current_embeddings = level_1_embeddings
# Convert to numpy array for clustering
current_embeddings_array = np.array(current_embeddings)
while len(current_texts) > 3 and current_level < 4: # Prevent infinite loops
print(f"\n Building Level {current_level + 1}...")
# Cluster current level
n_clusters = min(6, max(2, len(current_texts) // 2))
cluster_labels = cluster_with_gmm(current_embeddings_array, n_clusters)
# Add clusters to current level DataFrame (this is safe now)
if current_level in tree_levels:
tree_levels[current_level]['cluster'] = cluster_labels
print(f" Added cluster info to Level {current_level}")
# Generate summaries for next level
next_level = current_level + 1
next_summaries, next_metadata = generate_summaries_for_clusters(
current_texts, cluster_labels, next_level, llm
)
# Check if we got any summaries
if not next_summaries:
print(f" No summaries generated for Level {next_level}, stopping.")
break
# Create embeddings for next level
next_embeddings = create_embeddings_batch(next_summaries, embeddings)
# Create next level DataFrame
next_df = create_dataframe_for_level(
next_summaries,
next_embeddings,
next_metadata
)
# Add to tree
tree_levels[next_level] = next_df
print(f" Level {next_level} created with {len(next_df)} summaries")
# Prepare for next iteration
current_level = next_level
current_texts = next_summaries
current_embeddings = next_embeddings
current_embeddings_array = np.array(current_embeddings)
print(f"\n Final tree structure:")
for level, df in tree_levels.items():
content_type = "original documents" if level == 0 else f"level-{level} summaries"
print(f" Level {level}: {len(df)} {content_type}")
python
Building Level 2...
Clustering into 2 groups...
Added cluster info to Level 1
Generating summaries for Level 2...
Creating embeddings for 2 texts...
Created 2 embeddings
Level 2 created with 2 summaries
Final tree structure:
Level 0: 14 original documents
Level 1: 4 level-1 summaries
Level 2: 2 level-2 summaries
9. Create Unified Vectorstore
Now we have a multi-level tree, but we need a way to search across ALL levels simultaneously. Traditional search only looks at one level.
python
# Build unified FAISS vectorstore from all tree levels
print(" Building unified FAISS vectorstore...")
all_documents = []
level_distribution = {}
# Collect documents from all levels
for level, df in tree_levels.items():
print(f" Adding Level {level} to vectorstore...")
for _, row in df.iterrows():
doc = Document(
page_content=str(row['text']),
metadata=row['metadata']
)
all_documents.append(doc)
level_distribution[level] = len(df)
# Create FAISS vectorstore
vectorstore = FAISS.from_documents(all_documents, embeddings)
print(f" Vectorstore created with {len(all_documents)} total documents!")
print(f" Distribution across levels: {level_distribution}")
python
Building unified FAISS vectorstore...
Adding Level 0 to vectorstore...
Adding Level 1 to vectorstore...
Adding Level 2 to vectorstore...
Vectorstore created with 20 total documents!
Distribution across levels: {0: 14, 1: 4, 2: 2}
We combined all tree levels into a single FAISS vectorstore that can search across original documents, summaries, and high-level abstractions simultaneously.
The metadata keeps track of levels, allowing retrieval at different depths with one query.
10. Create Retriever with Contextual Compression
Raw similarity search often returns lengthy, unfocused results.
RAPTOR needs “smart” retrieval that not only finds relevant documents across tree levels but also extracts only the parts relevant to the specific query.
python
# Create contextual compression retriever
print(" Creating contextual compression retriever...")
# Base retriever
base_retriever = vectorstore.as_retriever(search_kwargs={"k": 8})
# Compression prompt to extract only relevant information
compression_prompt = ChatPromptTemplate.from_template(
"Given the context and question, extract only the information that's directly relevant to answering the question:\n\n"
"Context: {context}\n"
"Question: {question}\n\n"
"Relevant Information:"
)
# Create the extractor
extractor = LLMChainExtractor.from_llm(llm, prompt=compression_prompt)
# Create compression retriever
compression_retriever = ContextualCompressionRetriever(
base_compressor=extractor,
base_retriever=base_retriever
)
print(" Smart retriever created!")
python
Creating contextual compression retriever...
Smart retriever created!
Contextual compression uses an LLM to read retrieved documents and extract only query-relevant information. This prevents information overload and ensures we get focused, useful content for answer generation.
11. Testing the System
Now we test our complete system with real queries to observe how it pulls information from different tree levels and uses contextual compression.
python
def test_raptor_query(query, retriever, show_sources=True):
"""Test RAPTOR with a query and show detailed results."""
print(f"\n Testing query: '{query}'")
print("=" * 60)
# Retrieve documents
retrieved_docs = retriever.invoke(query)
if show_sources:
print(f"📄 Retrieved {len(retrieved_docs)} relevant documents:")
level_counts = {}
for i, doc in enumerate(retrieved_docs):
level = doc.metadata.get('level', 'unknown')
level_counts[level] = level_counts.get(level, 0) + 1
print(f"\n {i+1}. Level {level} | {doc.page_content[:120]}...")
print(f"\n Level distribution: {level_counts}")
# Generate answer
if retrieved_docs:
context = "\n\n".join([doc.page_content for doc in retrieved_docs])
answer_prompt = ChatPromptTemplate.from_template(
"Based on the following context, provide a comprehensive answer:\n\n"
"Context: {context}\n\n"
"Question: {question}\n\n"
"Answer:"
)
chain = answer_prompt | llm
result = chain.invoke({"context": context, "question": query})
answer = result.content if hasattr(result, 'content') else str(result)
print(f"\n RAPTOR Answer:")
print("-" * 40)
print(answer)
return {
"answer": answer,
"sources": len(retrieved_docs),
"levels_used": list(level_counts.keys()) if show_sources else []
}
else:
print(" No relevant documents found.")
return None
# Test with multiple queries
test_queries = [
"How do neural networks differ from traditional machine learning?",
"What are the main applications of AI in healthcare?",
"What are the ethical considerations in AI development?"
]
results = []
for query in test_queries:
result = test_raptor_query(query, compression_retriever)
if result:
results.append(result)
print(f" Used {result['sources']} sources from levels {result['levels_used']}")
python
Testing query: 'How do neural networks differ from traditional machine learning?'
============================================================
Retrieved 8 relevant documents:
1. Level 1 | Neural networks are a specialized area within machine learning that employ multi-layered artificial neural networks to d...
2. Level 0 | Neural networks differ from traditional machine learning in their ability to learn complex non-linear mappings from inpu...
3. Level 1 | Neural networks, particularly deep networks, differ from traditional machine learning by enabling the successful trainin...
4. Level 0 | Neural networks represent a subset of machine learning that utilizes multiple layers of artificial neurons to model and ...
5. Level 2 | Neural networks, particularly deep learning architectures, enable the training of very deep networks, which advance task...
6. Level 0 | The context provided does not explicitly address the differences between neural networks and traditional machine learnin...
7. Level 1 | The provided context does not contain specific information about how neural networks differ from traditional machine lea...
8. Level 0 | Neural networks are a subset of machine learning that utilize layers of interconnected nodes (neurons) to process data, ...
Level distribution: {1: 3, 0: 4, 2: 1}
RAPTOR Answer:
----------------------------------------
Neural networks differ from traditional machine learning in several fundamental ways, primarily concerning their structure, training capabilities, feature extraction methods, and performance on complex tasks. Here’s a comprehensive overview of these differences:
1. **Architectural Complexity**:
- **Neural Networks**: They employ a multi-layered architecture, often comprising numerous layers (foreach neural network) of interconnected artificial neurons (nodes). This layered approach enables them to model intricate data patterns and non-linear relationships effectively.
- **Traditional Machine Learning**: Algorithms typically use simpler structures and mathematical models, such as linear regression, decision trees, or support vector machines, which may not capture complex interactions in high-dimensional data.
2. **Feature Learning vs. Handcrafted Features**:
- **Neural Networks**: Neural networks automatically learn hierarchical feature representations from raw data through their layers. Each layer captures increasingly abstract features, allowing the model to adaptively discover and refine representations without manual intervention.
- **Traditional Machine Learning**: These methods often rely on handcrafted features, meaning that practitioners must manually select and engineer the input features used in the training process. This manual feature engineering can limit performance, as it may not capture all relevant patterns in the data.
3. **Training Techniques**:
- **Neural Networks**: Training, particularly in deep learning, often utilizes advanced techniques such as the backpropagation algorithm, which efficiently updates weights across multiple layers. This allows the model to learn from large datasets through optimization techniques such as stochastic gradient descent.
- **Traditional Machine Learning**: While traditional methods can also employ optimization, their training often doesn't require the same level of computational resources or complex backpropagation processes, as they typically involve simpler and faster-learning algorithms.
4. **Data Requirements**:
- **Neural Networks**: These models thrive on large amounts of labeled data and high computational power, often utilizing GPUs for faster training. They are designed to excel with vast datasets, learning complex patterns effectively.
- **Traditional Machine Learning**: These methods may perform adequately with smaller datasets and less complexity since they often rely on specified statistical assumptions and may struggle with large-scale intricate problems.
5. **Performance on Complex Tasks**:
- **Neural Networks**: They have demonstrated significant advancements in challenging tasks, such as image classification, natural language processing, object detection, and facial recognition, due to their ability to capture complex relationships and patterns in data.
- **Traditional Machine Learning**: Often, traditional techniques may be inadequate for such tasks without extensive feature engineering, and they may fail to achieve comparable accuracy or effectiveness on large and complex datasets.
6. **Adaptability and Generalization**:
- **Neural Networks**: They exhibit greater adaptability, learning representations of data that can generalize well across different but related tasks. This flexibility stems from their capacity to build deep, hierarchical models of data.
- **Traditional Machine Learning**: These methods may struggle with generalization due to their reliance on fixed feature sets and simpler modeling techniques, often resulting in limited flexibility in handling diverse data patterns.
In summary, neural networks represent a more advanced and flexible approach within the machine learning domain, characterized by their complex architectures, automatic feature learning capabilities, and superior performance on intricate tasks, especially when supplied with large datasets. In contrast, traditional machine learning methods typically involve simpler algorithms and manual feature engineering, placing them at a disadvantage in dealing with high-dimensional and complex data.
Used 8 sources from levels [1, 0, 2]
Testing query: 'What are the main applications of AI in healthcare?'
============================================================
Retrieved 8 relevant documents:
1. Level 1 | - AI applications enhance understanding of diseases and drug development.
- Companies like Atomwise use AI to predict co...
2. Level 2 | - AI improves disease understanding and drug development.
- Companies like Atomwise predict compound interactions for di...
3. Level 0 | The main applications of AI in healthcare include:
1. Diagnostic imaging
2. Drug discovery
3. Personalized treatment re...
4. Level 0 | The main applications of AI in healthcare include:
- Drug discovery and development, as seen with companies like Atomwis...
5. Level 0 | The context provided does not contain any information about the applications of AI in healthcare....
6. Level 1 | The context provided does not include specific applications of AI in healthcare....
7. Level 0 | The provided context does not contain specific information regarding the main applications of AI in healthcare....
8. Level 0 | The provided context does not contain any specific information about the main applications of AI in healthcare. Therefor...
Level distribution: {1: 2, 2: 1, 0: 5}
RAPTOR Answer:
----------------------------------------
The main applications of AI in healthcare include:
1. **Drug Discovery and Development**: AI plays a crucial role in accelerating drug discovery processes. Companies like Atomwise utilize AI to predict compound interactions for various diseases, including Ebola and multiple sclerosis. Additionally, firms like Recursion Pharmaceuticals and BenevolentAI leverage machine learning algorithms for identifying and repurposing drug candidates, which can significantly shorten the timeframe for bringing new therapies to market.
2. **Personalized Medicine**: Precision medicine aims to provide tailored treatment recommendations based on individual patient data. IBM Watson for Oncology is a notable example that offers personalized cancer treatment plans, although it faces challenges in clinical application. AI's ability to analyze vast datasets helps identify which treatments might be most effective for specific patient profiles.
3. **Drug Repurposing and Vaccine Development**: The COVID-19 pandemic has notably expedited the use of AI for drug repurposing and vaccine development. AI tools have been employed to screen existing drugs for their effectiveness against COVID-19, leading to the identification of effective treatments such as remdesivir and dexamethasone. Furthermore, AI has facilitated the accelerated development of vaccines.
4. **Epidemic Modeling and Contact Tracing**: AI technologies have been utilized for epidemic modeling to predict virus spread and optimize response strategies. Contact tracing applications developed during the pandemic also harness AI capabilities to track and manage illness spread, enhancing public health responses.
5. **Diagnostic Imaging**: AI enhances diagnostic imaging by analyzing medical images to identify conditions. Successful applications include diagnosing diabetic retinopathy from retinal photographs, conducting mammography screenings for breast cancer, analyzing chest X-rays for pneumonia detection, and interpreting CT scans for stroke diagnosis.
6. **Clinical Decision Support Systems**: AI-powered clinical decision support systems assist healthcare providers by analyzing patient data, recommending treatment options, and aiding in the diagnosis of diseases, ultimately improving patient outcomes and reducing costs.
7. **Remote Patient Monitoring and Telemedicine**: AI supports remote patient monitoring and telemedicine applications through digital health platforms, allowing for continuous patient engagement and care, especially crucial during the pandemic.
Overall, AI's ability to process large volumes of medical data and identify complex patterns significantly enhances healthcare delivery, leading to improved patient outcomes and operational efficiencies across various healthcare domains.
Used 8 sources from levels [1, 2, 0]
Testing query: 'What are the ethical considerations in AI development?'
============================================================
Retrieved 8 relevant documents:
1. Level 0 | The ethical considerations in AI development include:
1. **Algorithmic Bias**: The potential for machine learning syste...
2. Level 0 | The ethical considerations in AI development include ongoing collaboration between technologists, ethicists, policymaker...
3. Level 0 | The societal implications of AI development extend beyond technical achievements, encompassing economic, social, and eth...
4. Level 1 | Ethical concerns in AI development include algorithmic bias, where machine learning can reinforce societal biases found ...
5. Level 0 | The development of artificial general intelligence (AGI) and superintelligent systems has prompted discussions about exi...
6. Level 0 | The rapid advancement and deployment of artificial intelligence technologies have raised significant ethical concerns an...
7. Level 0 | The provided context does not contain any specific information regarding the ethical considerations in AI development....
8. Level 1 | The provided context does not contain any information specifically addressing ethical considerations in AI development....
Level distribution: {0: 6, 1: 2}
RAPTOR Answer:
----------------------------------------
The ethical considerations in AI development are multifaceted and crucial for ensuring that AI technologies benefit society while minimizing harm. Key areas of focus include:
1. **Algorithmic Bias**: AI systems can inherently reinforce and perpetuate existing societal biases present in training data. This is particularly evident in applications such as facial recognition, which may misidentify individuals based on race and gender, leading to discriminatory outcomes. Addressing algorithmic bias is essential to prevent unfair treatment and ensure equitable outcomes across diverse populations.
2. **Fairness**: Achieving fairness in AI systems is a major research area that seeks to define and implement equitable outcomes. Different methodologies exist to address fairness, such as fairness through awareness, which incorporates demographic information, and fairness through unawareness, which disregards it altogether. Statistical parity, another approach, aims to ensure proportional representation of different groups in decision-making processes.
3. **Transparency and Explainability**: The "black box" nature of many AI algorithms raises concerns about transparency and the ability to explain decisions made by these systems, especially in high-stakes scenarios (e.g., healthcare, criminal justice). The field of explainable AI (XAI) aims to provide tools and methods, such as LIME and SHAP, that make AI decision-making processes more interpretable and understandable to users, stakeholders, and regulators.
4. **Privacy Protection**: Protecting individual privacy is a fundamental ethical consideration in AI development. Techniques such as differential privacy allow for quantifying and controlling privacy risks, while approaches like federated learning enable model training without direct access to personal data. These practices aim to safeguard user information in the era of big data and AI.
5. **Collaborative Engagement**: The development of AI technologies necessitates ongoing collaboration between technologists, ethicists, policymakers, and civil society organizations. This collaboration is vital to address safety, fairness, and alignment of AI systems with human values. It also emphasizes the importance of inclusive AI practices that ensure equitable access to AI benefits and mitigate potential harms, addressing issues such as the digital divide.
6. **Societal Implications**: The broader societal implications of AI development—such as job displacement, privacy erosion, bias reinforcement, and the consolidation of power among a few technology companies—must also be considered. Ethical AI development involves recognizing and responding to these complex challenges, requiring thoughtful engagement from researchers, policymakers, and the public.
7. **Existential Risks and Long-term Safety**: The emergence of advanced AI, including artificial general intelligence (AGI) and superintelligent systems, brings about discussions concerning existential risks. Researchers emphasize the significance of resolving AI alignment problems—ensuring that AI objectives align with human intentions—prior to advancing towards more complex AI systems. Organizations dedicated to long-term AI safety focus on developing robust techniques like reward modeling and cooperative inverse reinforcement learning.
In summary, ethical considerations in AI development encompass a broad array of issues related to bias, fairness, transparency, privacy, collaboration, societal impact, and long-term safety. Addressing these concerns is imperative for creating AI systems that are just, trustworthy, and beneficial for all.
Used 8 sources from levels [0, 1]
12. Compare RAPTOR vs Traditional RAG
To truly understand RAPTOR’s value, we need to see how it compares to traditional RAG with the same data.
python
def compare_rag_systems(query):
"""Compare RAPTOR with traditional flat RAG."""
print(f"\n Comparing systems with: '{query}'")
print("=" * 70)
# Traditional RAG setup
traditional_docs = [Document(page_content=text, metadata={"source": "traditional"})
for text in texts]
traditional_vectorstore = FAISS.from_documents(traditional_docs, embeddings)
traditional_results = traditional_vectorstore.similarity_search(query, k=3)
# RAPTOR results
raptor_results = compression_retriever.invoke(query)[:3]
print(" TRADITIONAL RAG:")
for i, doc in enumerate(traditional_results, 1):
print(f" {i}. {doc.page_content[:120]}...")
print("\n RAPTOR SYSTEM:")
for i, doc in enumerate(raptor_results, 1):
level = doc.metadata.get('level', '?')
origin = doc.metadata.get('origin', 'summary')
print(f" {i}. [Level {level}] {doc.page_content[:120]}...")
# Compare systems
compare_rag_systems("What are the main applications of AI in healthcare?")
python
Comparing systems with: 'What are the main applications of AI in healthcare?'
======================================================================
TRADITIONAL RAG:
1. The success of AlphaGo was built upon the combination of Monte Carlo Tree Search with deep
neural networks. The system u...
2. amino acid sequences, has potential implications for understanding disease mechanisms and
designing new therapeutic inte...
3. demand. Walmart and other major retailers use AI for inventory management, predicting demand
for products across differe...
RAPTOR SYSTEM:
1. [Level 1] - AI applications enhance understanding of diseases and drug development.
- Companies like Atomwise use AI to predict co...
2. [Level 2] - AI improves disease understanding and drug development.
- Companies like Atomwise predict compound interactions for di...
3. [Level 0] The main applications of AI in healthcare include diagnostic imaging, drug discovery, personalized treatment recommendat...
Traditional RAG only returns chunks from original documents, while RAPTOR provides information from multiple abstraction levels with contextual compression, offering both specific details and high-level context in a single response.
Free Course
Master Core Python — Your First Step into AI/ML
Build a strong Python foundation with hands-on exercises designed for aspiring Data Scientists and AI/ML Engineers.
Start Free Course →Trusted by 50,000+ learners
Related Course
Master Gen AI — Hands-On
Join 5,000+ students at edu.machinelearningplus.com
Explore Course

