machine learning +
Build a Python AI Chatbot with Memory Using LangChain
Building Reliable RAG Systems: Adding Validation Layers for Accurate AI Answers
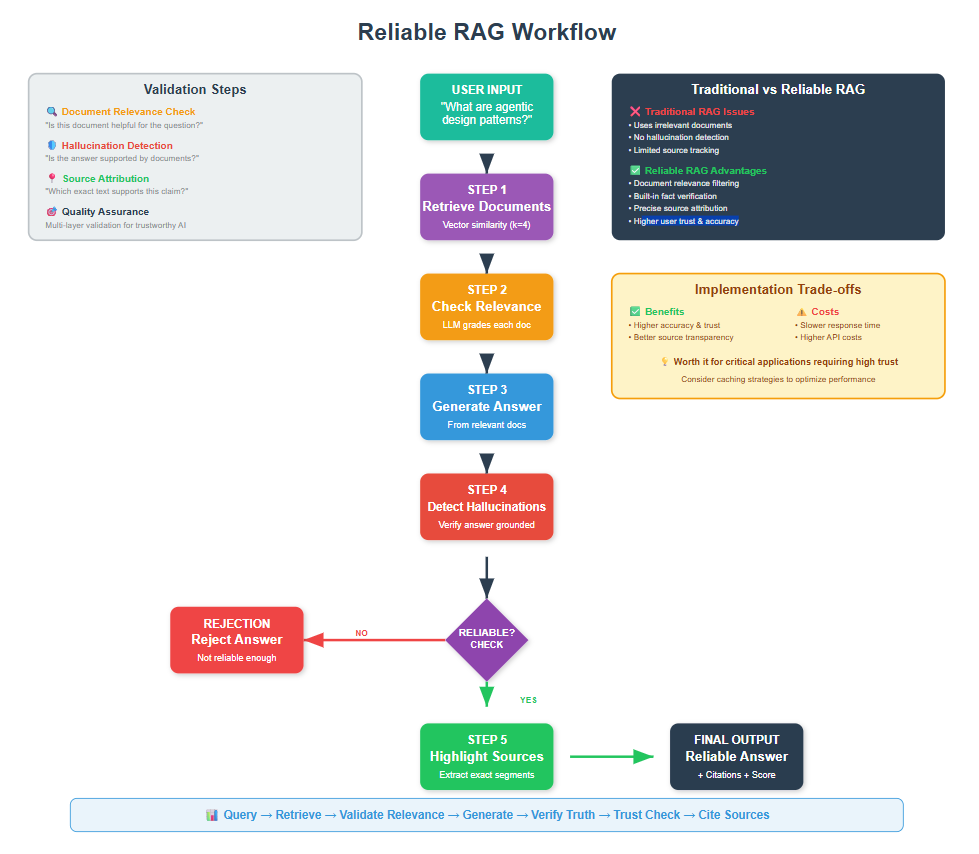
Reliable RAG is an enhanced Retrieval-Augmented Generation approach that adds multiple validation layers to ensure your AI system gives accurate, relevant, and trustworthy answers. Instead of just retrieving documents and generating responses, Reliable RAG checks document relevance, detects hallucinations, and highlights exactly which sources support each answer
Reliable RAG is an enhanced Retrieval-Augmented Generation approach that adds multiple validation layers to ensure your AI system gives accurate, relevant, and trustworthy answers. Instead of just retrieving documents and generating responses, Reliable RAG checks document relevance, detects hallucinations, and highlights exactly which sources support each answer.
Have you ever asked a RAG-based chatbot a question and gotten an answer that sounded confident but felt wrong? Then you had to rephrase your question multiple times, going through several iterations just to get something useful?
This frustrating experience happens when your RAG system retrieves irrelevant documents or when the AI hallucinates facts that aren’t actually in your knowledge base.
Reliable RAG provides a systematic solution to this problem.
Instead of hoping your AI gives good answers, you get guarantees through multiple validation checkpoints.
1. The Problem We’re Solving
Let me paint you a picture. You have a knowledge base about your products, and a customer asks: “What’s the warranty policy for the Pro model?”
Traditional RAG systems take your question, find some documents that mention “warranty” and “Pro,” then generate an answer. But here’s what often goes wrong:
- Retrieved documents aren’t actually relevant – maybe they mention warranty for a different product
- The AI fills in gaps with plausible-sounding but incorrect information
- You have no way to verify which parts of the answer are actually supported by your documents
Reliable RAG fixes this by adding three critical checkpoints:
The result? Your customer gets confident-sounding misinformation, which damages trust and could create real problems.
- Document Relevance Verification – Is this document actually helpful for the question?
- Hallucination Detection – Is the generated answer actually supported by the documents?
- Source Attribution – Which exact text segments support each claim?
2. Setting Up Your Environment
Before we build our reliable system, let’s get everything set up properly. We’ll need some additional packages beyond basic RAG for confidence scoring and verification.
I’ll assume you have Python and VS Code ready to go.
First, let’s install the packages we need:
bash
conda create -p rag python==3.12
conda activate rag
pip install ipykernel
pip install openai faiss-cpu langchain python-dotenv tiktoken numpy pypdf
Now let’s import everything we need:
python
import os
import numpy as np
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import TextLoader
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.vectorstores import FAISS
from langchain.prompts import PromptTemplate, ChatPromptTemplate
from langchain.schema import Document
from langchain_core.output_parsers import StrOutputParser
from pydantic import BaseModel, Field
from typing import List
import textwrap
# Load your environment variables
load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv('OPENAI_API_KEY')
Make sure you have your .env file with your OpenAI API key:
python
OPENAI_API_KEY=your_api_key_here
3. Loading and Processing Your PDF Document
Let’s load your PDF and extract its content. This is where we’ll build our knowledge base from your actual document.
You can download the pdf here
python
# Set the path to your PDF
pdf_path = "Neural Networks.pdf" # Update this to your actual PDF path
# Load the PDF document
print("Loading PDF...")
pdf_loader = PyPDFLoader(pdf_path)
raw_documents = pdf_loader.load()
print(f"Loaded {len(raw_documents)} pages from the Neural Networks PDF")
print(f"First page preview: {raw_documents[0].page_content[:300]}...")
# Let's also check what metadata we have
print(f"Document metadata: {raw_documents[0].metadata}")
python
Loading PDF...
Loaded 51 pages from the Neural Networks PDF
First page preview: Comprehensive Guide to Neural Networks
Table of Contents
1. Introduction to Neural Networks
2. Historical Development and Evolution
3. Mathematical Foundations
4. Basic Neural Network Architecture
5. Learning Algorithms and Training
6. Activation Functions and Optimization
7. Deep Learning and Deep ...
Document metadata: {'producer': 'Skia/PDF m136', 'creator': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36', 'creationdate': '2025-05-29T08:55:52+00:00', 'title': 'Comprehensive Guide to Neural Networks', 'moddate': '2025-05-29T08:55:52+00:00', 'source': 'Neural Networks.pdf', 'total_pages': 51, 'page': 0, 'page_label': '1'}
The PyPDFLoader reads each page of your PDF as a separate document. This gives us access to all the neural networks content you want to use as your knowledge base.
4. Chunking Your Neural Networks Document
Now we need to break your PDF content into smaller chunks. This is important because you don’t want to return entire pages when someone asks a specific question – you want focused, relevant segments.
python
# Configure our text splitter for the content
chunk_size = 500 # characters per chunk - good for technical content
chunk_overlap = 100 # overlap between chunks to maintain context
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
separators=["\n\n", "\n", " ", ""] # Try these separators in order
)
# Split the document into chunks
document_chunks = text_splitter.split_documents(raw_documents)
print(f"Split {len(raw_documents)} pages into {len(document_chunks)} chunks")
print(f"Sample chunk: {document_chunks[0].page_content[:200]}...")
# Let's examine a few chunks to understand our content
print("\nExamining document chunks:")
for i, chunk in enumerate(document_chunks[:3]):
print(f"\nChunk {i+1}:")
print(f"Content: {chunk.page_content[:150]}...")
print(f"Page: {chunk.metadata.get('page', 'Unknown')}")
python
Split 51 pages into 360 chunks
Sample chunk: Comprehensive Guide to Neural Networks
Table of Contents
1. Introduction to Neural Networks
2. Historical Development and Evolution
3. Mathematical Foundations
4. Basic Neural Network Architecture
5. ...
Examining document chunks:
Chunk 1:
Content: Comprehensive Guide to Neural Networks
Table of Contents
1. Introduction to Neural Networks
2. Historical Development and Evolution
3. Mathematical Fo...
Page: 0
Chunk 2:
Content: 11. Training Techniques and Regularization
12. Applications Across Industries
13. Tools, Frameworks, and Implementation
14. Challenges and Limitations...
Page: 0
Chunk 3:
Content: machine learning, offering a computational approach inspired by the structure and function of
biological neural networks in the human brain. These pow...
Page: 0
The RecursiveCharacterTextSplitter is intelligent about where it breaks text. It tries to split on paragraphs first, then sentences, then words.
5. Creating Your Vector Store with FAISS
Now we need to convert our neural networks text chunks into vectors (numerical representations) and store them in a searchable format.
We’ll use OpenAI’s embedding model and FAISS for efficient similarity search.
python
# Initialize OpenAI embeddings
embeddings_model = OpenAIEmbeddings(model="text-embedding-3-small")
# Create vector store using FAISS with your content
print("Creating embeddings for neural networks content and building FAISS index...")
print("This may take a moment depending on the size of your PDF...")
vector_store = FAISS.from_documents(
documents=document_chunks,
embedding=embeddings_model
)
print(f"Created vector store with {len(document_chunks)} neural networks document chunks")
# Test the vector store with a query
test_query = "How does backpropagation work?"
similar_docs = vector_store.similarity_search(test_query, k=3)
print(f"Found {len(similar_docs)} similar documents for neural networks test query")
# Let's see what we retrieved
print("\nRetrieved chunks for backpropagation query:")
for i, doc in enumerate(similar_docs):
print(f"Chunk {i+1}: {doc.page_content[:200]}...")
python
Creating embeddings for neural networks content and building FAISS index...
This may take a moment depending on the size of your PDF...
Created vector store with 360 neural networks document chunks
Found 3 similar documents for neural networks test query
Retrieved chunks for backpropagation query:
Chunk 1: The breakthrough came with the development of the backpropagation algorithm, independently
discovered by several researchers including David Rumelhart, Geoffrey Hinton, and Ronald Williams,
who publis...
Chunk 2: derivatives indicate the direction and magnitude of change needed to reduce the loss function.
The chain rule is fundamental to backpropagation, the primary algorithm used to train neural
networks. Th...
Chunk 3: backward through the network layers.
The backpropagation algorithm revolutionized neural network training by making it possible to
train deep, multi-layer networks effectively. This development led to...
FAISS (Facebook AI Similarity Search) is like a super-fast librarian that can instantly find the most similar documents to any query.
It uses mathematical similarity (cosine similarity) to find matches, which means it understands meaning, not just keywords.
6. Setting Up the Language Model
Let’s initialize our OpenAI language model that we’ll use for various tasks throughout the Reliable RAG pipeline
python
# Initialize our language model
llm_model = ChatOpenAI(
temperature=0, # We want consistent, focused responses
model="gpt-4o-mini", # Good balance of quality and cost
max_tokens=1000
)
print("Language model initialized successfully")
python
Language model initialized successfully
7. Building the Document Relevance Checker
This is where Reliable RAG starts to differentiate itself from traditional RAG.
Instead of blindly using whatever neural networks chunks we retrieve, we’ll check if they’re actually relevant to the user’s question.
python
# Data model for relevance checking
class GradeDocuments(BaseModel):
"""Binary score for relevance check on retrieved documents."""
binary_score: str = Field(
description="Documents are relevant to the question, 'yes' or 'no'"
)
# Create a prompt template for relevance checking
relevance_prompt = ChatPromptTemplate.from_messages([
("system", """You are a grader assessing relevance of a retrieved document to a user question.
If the document contains keyword(s) or semantic meaning related to the user question, grade it as relevant.
It does not need to be a stringent test. The goal is to filter out erroneous retrievals.
Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question."""),
("human", "Retrieved document: \n\n {document} \n\n User question: {question}")
])
# Create the relevance grader
def create_relevance_grader():
"""Create a function to grade document relevance"""
structured_llm_grader = llm_model.with_structured_output(GradeDocuments)
return relevance_prompt | structured_llm_grader
retrieval_grader = create_relevance_grader()
print("Document relevance checker created for neural networks content")
python
Document relevance checker created for neural networks content
This relevance checker acts as a quality control gate specifically tuned for our content.
It uses the LLM to evaluate whether each retrieved document chunk actually helps answer the user’s question about the concepts.
8. Testing Document Relevance Checking
Let’s test our relevance checker to see how it works with queries
python
def test_relevance_checking_neural_networks(question, vector_store, k=4):
"""Test the relevance checking functionality with the content"""
print(f"Testing relevance checking for: '{question}'")
print("="*50)
# Retrieve documents
docs = vector_store.similarity_search(question, k=k)
relevant_docs = []
for i, doc in enumerate(docs):
print(f"\nDocument {i+1}:")
print(f"Page: {doc.metadata.get('page', 'Unknown')}")
print(f"Content: {doc.page_content[:150]}...")
# Grade the document for relevance
grade = retrieval_grader.invoke({
"question": question,
"document": doc.page_content
})
print(f"Relevance Grade: {grade.binary_score}")
if grade.binary_score == 'yes':
relevant_docs.append(doc)
print("-" * 30)
print(f"\nSummary: {len(relevant_docs)} out of {len(docs)} documents were relevant")
return relevant_docs
# Test the relevance checking with questions
test_questions = [
"How does backpropagation work?",
"What are activation functions?",
"Explain gradient descent"
]
for question in test_questions:
print(f"\n{'='*60}")
relevant_docs = test_relevance_checking_neural_networks(question, vector_store)
print(f"{'='*60}")
python
============================================================
Testing relevance checking for: 'How does backpropagation work?'
==================================================
Document 1:
Page: 4
Content: The breakthrough came with the development of the backpropagation algorithm, independently
discovered by several researchers including David Rumelhart...
Relevance Grade: yes
------------------------------
Document 2:
Page: 8
Content: derivatives indicate the direction and magnitude of change needed to reduce the loss function.
The chain rule is fundamental to backpropagation, the p...
Relevance Grade: yes
------------------------------
Document 3:
Page: 4
Content: backward through the network layers.
The backpropagation algorithm revolutionized neural network training by making it possible to
train deep, multi-l...
Relevance Grade: yes
------------------------------
Document 4:
Page: 19
Content: networks by computing gradients through the chain rule of calculus.
The forward pass computes network outputs by propagating input data through succes...
Relevance Grade: yes
------------------------------
Summary: 4 out of 4 documents were relevant
============================================================
============================================================
Testing relevance checking for: 'What are activation functions?'
==================================================
Document 1:
Page: 22
Content: Activation functions introduce non-linearity into neural networks, transforming the linear
combinations of inputs and weights into outputs that can re...
Relevance Grade: yes
------------------------------
Document 2:
Page: 22
Content: Activation functions and optimization techniques represent two critical components that determine
the success of neural network training and the quali...
Relevance Grade: yes
------------------------------
Document 3:
Page: 24
Content: Adaptive activation functions allow networks to learn optimal activation shapes during training,
either through parameterized functions or by learning...
Relevance Grade: yes
------------------------------
Document 4:
Page: 23
Content: Computational efficiency of activation functions affects training and inference speed, particularly
important for large networks or resource-constrain...
Relevance Grade: yes
------------------------------
Summary: 4 out of 4 documents were relevant
============================================================
============================================================
Testing relevance checking for: 'Explain gradient descent'
==================================================
Document 1:
Page: 18
Content: Mini-batch gradient descent represents a compromise between batch and stochastic approaches,
using small subsets of the training data to compute gradi...
Relevance Grade: yes
------------------------------
Document 2:
Page: 8
Content: backward through the network.
Gradient descent and its variants form the core of neural network optimization. The basic gradient
descent algorithm upd...
Relevance Grade: yes
------------------------------
Document 3:
Page: 17
Content: Gradient Descent and Optimization
Gradient descent forms the foundation of neural network training, providing a systematic method
for adjusting networ...
Relevance Grade: yes
------------------------------
Document 4:
Page: 18
Content: The gradient descent algorithm computes the gradient of the loss function with respect to each
network parameter, indicating the direction and magnitu...
Relevance Grade: yes
------------------------------
Summary: 4 out of 4 documents were relevant
============================================================
This test function shows you exactly how the relevance checking works with your content.
You’ll see each retrieved document, its relevance grade, and which documents make it through the filter.
9. Creating the Answer Generation System
Now let’s create the system that generates answers from our filtered, relevant documents
python
def create_answer_generator():
"""Create the answer generation system for the PDF content"""
# Prompt for generating answers about the content
answer_prompt = ChatPromptTemplate.from_messages([
("system", """You are an expert assistant for neural networks and deep learning questions.
Answer the question based on the provided documents from a neural networks textbook or paper.
Use three to five sentences maximum and keep the answer concise but technically accurate.
If you cannot answer the question based on the provided documents, say so clearly."""),
("human", "Retrieved documents: \n\n {documents} \n\n User question: {question}")
])
return answer_prompt | llm_model | StrOutputParser()
# Helper function to format documents
def format_docs_for_prompt(docs):
"""Format documents for inclusion in prompts"""
return "\n\n".join([
f"Document {i+1} (Page {doc.metadata.get('page', 'Unknown')}):\n{doc.page_content}"
for i, doc in enumerate(docs)
])
# Create the answer generator
answer_generator = create_answer_generator()
print("Answer generation system created for neural networks content")
python
Answer generation system created for neural networks content
The answer generation system is designed to be conservative and technically accurate – it will only answer neural networks questions based on the provided documents and will admit when it doesn’t have enough information.
10. Building the Hallucination Detector
This is one of the most important components of Reliable RAG.
We need to verify that the generated answers is actually supported by the documents we provided, not made up by the AI.
python
# Data model for hallucination detection
class GradeHallucinations(BaseModel):
"""Binary score for hallucination present in generation answer."""
binary_score: str = Field(
description="Answer is grounded in the facts, 'yes' or 'no'"
)
def create_hallucination_detector():
"""Create the hallucination detection system for the content"""
hallucination_prompt = ChatPromptTemplate.from_messages([
("system", """You are a grader assessing whether an LLM generation about neural networks is grounded in / supported by a set of retrieved facts.
Give a binary score 'yes' or 'no'. 'Yes' means that the answer is grounded in / supported by the set of facts.
Be especially careful with technical neural networks concepts - do not penalize for minor stylistic differences or reasonable technical inferences, but do penalize for factual claims about neural networks not supported by the documents."""),
("human", "Set of facts: \n\n {documents} \n\n LLM generation: {generation}")
])
structured_llm_grader = llm_model.with_structured_output(GradeHallucinations)
return hallucination_prompt | structured_llm_grader
hallucination_detector = create_hallucination_detector()
print("Hallucination detection system created for neural networks content")
python
Hallucination detection system created for neural networks content
This system checks whether the AI’s response about the query is actually supported by the source documents from your PDF.
It’s your safety net against confident-sounding but incorrect technical explanations.
11. Creating the Source Highlighter
The final component identifies exactly which parts of your PDF were used to generate the answer. This provides transparency and allows users to verify technical claims.
python
# Data model for source highlighting
class HighlightDocuments(BaseModel):
"""Identify specific parts of documents used for answering the question."""
document_segments: List[str] = Field(
description="List of exact text segments from documents that support the answer"
)
page_references: List[str] = Field(
description="List of page numbers where the supporting segments were found"
)
reasoning: str = Field(
description="Brief explanation of how these segments support the answer"
)
def create_source_highlighter():
"""Create the source highlighting system for the content"""
highlight_prompt = ChatPromptTemplate.from_messages([
("system", """You are an expert at identifying which parts of neural networks documents were used to generate an answer.
Your task is to:
1. Identify the specific text segments from the provided neural networks documents that directly support the generated answer
2. Extract these segments word-for-word (no paraphrasing)
3. Note which page each segment comes from
4. Explain briefly how these segments support the answer
Be precise and only include segments that directly relate to the neural networks answer."""),
("human", """Documents: \n\n {documents} \n\n Generated Answer: {answer} \n\n Question: {question}""")
])
structured_llm_highlighter = llm_model.with_structured_output(HighlightDocuments)
return highlight_prompt | structured_llm_highlighter
source_highlighter = create_source_highlighter()
print("Source highlighting system created for the content")
python
Source highlighting system created for the content
Source highlighting provides complete transparency for your content.
Users can see exactly which text segments and pages support each part of the answer, enabling them to go back to the original PDF for more context.
12. Building the Complete Reliable RAG Pipeline
Now let’s put all the pieces together into a comprehensive function that runs the entire Reliable RAG process on your content
python
def reliable_rag_neural_networks(question, vector_store, k=4, show_details=True):
"""
Complete Reliable RAG pipeline for our content with all validation steps
"""
if show_details:
print(f" Neural Networks Question: {question}")
print("\n Step 1: Retrieving relevant content...")
# Step 1: Retrieve documents using similarity search
retrieved_docs = vector_store.similarity_search(question, k=k)
if show_details:
print(f"Retrieved {len(retrieved_docs)} document chunks from neural networks PDF")
print("\n Step 2: Checking document relevance...")
# Step 2: Filter for relevance
relevant_docs = []
for i, doc in enumerate(retrieved_docs):
grade = retrieval_grader.invoke({
"question": question,
"document": doc.page_content
})
if show_details:
page_info = doc.metadata.get('page', 'Unknown')
print(f"Chunk {i+1} (Page {page_info}): {grade.binary_score}")
if grade.binary_score == 'yes':
relevant_docs.append(doc)
if not relevant_docs:
return {
"answer": "I couldn't find relevant content in the document to answer your question.",
"confidence": "low",
"sources": [],
"pages": [],
"reasoning": "No relevant documents found",
"validation_passed": False,
"documents_checked": len(retrieved_docs),
"relevant_documents": 0
}
if show_details:
print(f"\n {len(relevant_docs)} relevant chunks found")
print("\n Step 3: Generating answer from the content...")
# Step 3: Generate answer from relevant documents
formatted_docs = format_docs_for_prompt(relevant_docs)
generated_answer = answer_generator.invoke({
"documents": formatted_docs,
"question": question
})
if show_details:
print("\n Step 4: Checking for hallucinations...")
# Step 4: Check for hallucinations
hallucination_check = hallucination_detector.invoke({
"documents": formatted_docs,
"generation": generated_answer
})
if show_details:
print(f"Hallucination check: {hallucination_check.binary_score}")
if hallucination_check.binary_score == 'no':
return {
"answer": "I cannot provide a confident answer as my response may not be fully supported by the document.",
"confidence": "low",
"sources": [],
"pages": [],
"reasoning": "Generated answer failed hallucination check",
"validation_passed": False,
"documents_checked": len(retrieved_docs),
"relevant_documents": len(relevant_docs)
}
if show_details:
print("\n Step 5: Highlighting source segments from the PDF...")
# Step 5: Identify source segments
try:
source_analysis = source_highlighter.invoke({
"documents": formatted_docs,
"answer": generated_answer,
"question": question
})
source_segments = source_analysis.document_segments
page_references = source_analysis.page_references
reasoning = source_analysis.reasoning
except Exception as e:
if show_details:
print(f"Could not highlight sources: {e}")
source_segments = []
page_references = []
reasoning = "Source highlighting unavailable"
# Return comprehensive results
return {
"answer": generated_answer,
"confidence": "high",
"sources": source_segments,
"pages": page_references,
"reasoning": reasoning,
"validation_passed": True,
"documents_checked": len(retrieved_docs),
"relevant_documents": len(relevant_docs)
}
This pipeline runs all the steps of Reliable RAG specifically for your PDF, providing detailed feedback at each stage so you can understand exactly what’s happening with your technical content.
13. Testing the Complete System
Let’s test our complete Reliable RAG system with some queries
python
def test_neural_networks_rag():
"""Test the complete Reliable RAG system with questions"""
# Neural networks specific test questions
neural_networks_questions = [
"How does backpropagation work?",
"What are activation functions in neural networks?",
"What is the capital of Mars?" # This should fail gracefully
]
print(" TESTING RELIABLE RAG WITH CONTENT")
print("="*80)
for question in neural_networks_questions:
print(f"\n{'='*80}")
print(f"TESTING: {question}")
print("="*80)
result = reliable_rag_neural_networks(question, vector_store, show_details=True)
print("\n" + " FINAL RESULT:")
print("-" * 40)
print(f"Answer: {result['answer']}")
print(f"Confidence: {result['confidence']}")
print(f"Validation Passed: {result['validation_passed']}")
if result['sources']:
print("\nSupporting Evidence from PDF:")
for i, (source, page) in enumerate(zip(result['sources'], result['pages']), 1):
print(f"{i}. Page {page}: \"{source[:100]}...\"")
if result['reasoning']:
print(f"\nReasoning: {result['reasoning']}")
print(f"\nDocs Checked: {result.get('documents_checked', 0)}")
print(f"Relevant Docs: {result.get('relevant_documents', 0)}")
print("\n" + "-" * 40)
# Run the neural networks tests
test_neural_networks_rag()
python
TESTING RELIABLE RAG WITH CONTENT
================================================================================
================================================================================
TESTING: How does backpropagation work?
================================================================================
Neural Networks Question: How does backpropagation work?
Step 1: Retrieving relevant content...
Retrieved 4 document chunks from neural networks PDF
Step 2: Checking document relevance...
Chunk 1 (Page 4): yes
Chunk 2 (Page 8): yes
Chunk 3 (Page 4): yes
Chunk 4 (Page 19): yes
4 relevant chunks found
Step 3: Generating answer from the content...
Step 4: Checking for hallucinations...
Hallucination check: yes
Step 5: Highlighting source segments from the PDF...
FINAL RESULT:
----------------------------------------
Answer: Backpropagation works by computing gradients of the loss function with respect to the network's weights through a two-step process: the forward pass and the backward pass. In the forward pass, input data is propagated through the network to produce outputs, which are then compared to target values to calculate the loss. During the backward pass, the algorithm uses the chain rule to propagate error signals backward through the network, computing gradients at each layer. These gradients indicate the direction and magnitude of weight adjustments needed to minimize the loss function, allowing for effective training of multi-layer networks.
Confidence: high
Validation Passed: True
Supporting Evidence from PDF:
1. Page 19: "The forward pass computes network outputs by propagating input data through successive layers, compu..."
2. Page 8: "The backward pass computes gradients by propagating error signals backward through the network, star..."
3. Page 8: "The chain rule is fundamental to backpropagation, the primary algorithm used to train neural network..."
Reasoning: These segments explain the two-step process of backpropagation: the forward pass, where input data is processed to produce outputs and calculate loss, and the backward pass, where gradients are computed using the chain rule to adjust weights. This directly supports the generated answer by detailing how backpropagation functions in neural networks.
Docs Checked: 4
Relevant Docs: 4
----------------------------------------
================================================================================
TESTING: What are activation functions in neural networks?
================================================================================
Neural Networks Question: What are activation functions in neural networks?
Step 1: Retrieving relevant content...
Retrieved 4 document chunks from neural networks PDF
Step 2: Checking document relevance...
Chunk 1 (Page 22): yes
Chunk 2 (Page 22): yes
Chunk 3 (Page 12): yes
Chunk 4 (Page 24): yes
4 relevant chunks found
Step 3: Generating answer from the content...
Step 4: Checking for hallucinations...
Hallucination check: yes
Step 5: Highlighting source segments from the PDF...
FINAL RESULT:
----------------------------------------
Answer: Activation functions in neural networks are mathematical functions that introduce non-linearity into the model, allowing it to learn complex patterns and relationships that linear models cannot capture. They transform the linear combinations of inputs and weights into outputs, enabling the network to approximate intricate functions. Without activation functions, neural networks would be limited to learning only linear mappings, significantly restricting their representational power.
Confidence: high
Validation Passed: True
Supporting Evidence from PDF:
1. Page 22: "Activation functions introduce non-linearity into neural networks, transforming the linear combinati..."
2. Page 12: "The activation function introduces non-linearity into the neuron's computation, enabling neural netw..."
Reasoning: These segments directly explain the role of activation functions in introducing non-linearity to neural networks, which allows them to learn complex patterns and relationships. They also highlight the limitations of neural networks without activation functions, supporting the generated answer's claims about their importance.
Docs Checked: 4
Relevant Docs: 4
----------------------------------------
================================================================================
TESTING: What is the capital of Mars?
================================================================================
Neural Networks Question: What is the capital of Mars?
Step 1: Retrieving relevant content...
Retrieved 4 document chunks from neural networks PDF
Step 2: Checking document relevance...
Chunk 1 (Page 49): no
Chunk 2 (Page 17): no
Chunk 3 (Page 1): no
Chunk 4 (Page 49): no
FINAL RESULT:
----------------------------------------
Answer: I couldn't find relevant content in the document to answer your question.
Confidence: low
Validation Passed: False
Reasoning: No relevant documents found
Docs Checked: 4
Relevant Docs: 0
----------------------------------------
This test suite shows how Reliable RAG handles both answerable questions (where it provides confident, validated answers with page references) and unanswerable questions (where it admits it doesn’t have enough information).
14. Comparing Traditional RAG vs Reliable RAG
Let’s create a simple traditional RAG system to compare against our Reliable RAG using your content
python
def traditional_rag_neural_networks(question, vector_store, k=4):
"""Traditional RAG without validation steps for content"""
# Just retrieve and generate - no validation
docs = vector_store.similarity_search(question, k=k)
formatted_docs = format_docs_for_prompt(docs)
simple_prompt = ChatPromptTemplate.from_messages([
("system", "You are an expert in neural networks. Answer the question based on the provided documents."),
("human", "Documents: {documents} \n\n Question: {question}")
])
simple_chain = simple_prompt | llm_model | StrOutputParser()
answer = simple_chain.invoke({"documents": formatted_docs, "question": question})
return answer
def compare_rag_approaches_neural_networks(question):
"""Compare traditional RAG vs Reliable RAG for the content"""
print(f"COMPARISON FOR NEURAL NETWORKS QUESTION: {question}")
print("="*70)
print("\n TRADITIONAL RAG:")
print("-" * 30)
traditional_answer = traditional_rag_neural_networks(question, vector_store)
print(traditional_answer)
print("\n RELIABLE RAG:")
print("-" * 30)
reliable_result = reliable_rag_neural_networks(question, vector_store, show_details=False)
print(f"Answer: {reliable_result['answer']}")
print(f"Confidence: {reliable_result['confidence']}")
print(f"Validation: {' Passed' if reliable_result['validation_passed'] else ' Failed'}")
if reliable_result['pages']:
print(f"Source Pages: {', '.join(reliable_result['pages'])}")
# Compare the approaches with neural networks questions
comparison_questions = [
"What is a neural network?",
"What is the ROI calculation for implementing neural networks in supply chain optimization?", # Potentially problematic question
"How do you handle numerical instability in very deep networks with 500+ layers?"
]
for question in comparison_questions:
compare_rag_approaches_neural_networks(question)
print("\n" + "="*70 + "\n")
python
COMPARISON FOR NEURAL NETWORKS QUESTION: What is a neural network?
======================================================================
TRADITIONAL RAG:
------------------------------
A neural network is a computational system composed of interconnected nodes, known as neurons or units, that work together to process information and learn from data. Unlike traditional programming methods that rely on explicit instructions to solve specific problems, neural networks learn to perform tasks by analyzing examples and automatically discovering patterns and relationships within the data. They utilize mathematical operations involving weighted connections between nodes, activation functions to determine outputs, and learning algorithms to adjust connection weights based on training data. This structure allows neural networks to effectively tackle a wide range of applications.
RELIABLE RAG:
------------------------------
Answer: A neural network is a computational system composed of interconnected nodes, known as neurons, that work together to process information and learn from data. Unlike traditional programming, neural networks learn to perform tasks by analyzing examples and discovering patterns within the data. They consist of artificial neurons that compute weighted sums of inputs, apply activation functions, and adjust connection weights through learning algorithms based on training data.
Confidence: high
Validation: Passed
Source Pages: 0, 0, 12, 1
======================================================================
COMPARISON FOR NEURAL NETWORKS QUESTION: What is the ROI calculation for implementing neural networks in supply chain optimization?
======================================================================
TRADITIONAL RAG:
------------------------------
The provided documents do not contain specific information regarding the ROI (Return on Investment) calculation for implementing neural networks in supply chain optimization. However, I can provide a general framework for how one might approach calculating ROI in this context.
1. **Identify Costs**:
- **Initial Investment**: Costs associated with acquiring hardware, software, and data storage.
- **Development Costs**: Expenses related to hiring data scientists, engineers, and other personnel to develop and implement the neural network models.
- **Training Costs**: Resources needed for training the models, including computational power and time.
- **Maintenance Costs**: Ongoing costs for maintaining the models, updating them, and ensuring they continue to perform well.
2. **Estimate Benefits**:
- **Efficiency Gains**: Quantify improvements in supply chain processes, such as reduced lead times, optimized inventory levels, and improved demand forecasting.
- **Cost Savings**: Calculate savings from reduced waste, lower operational costs, and improved resource allocation.
- **Revenue Increases**: Assess potential increases in sales due to better customer satisfaction and service levels resulting from optimized supply chain operations.
3. **Calculate ROI**:
- Use the formula:
\[
\text{ROI} = \frac{\text{Net Benefits}}{\text{Total Costs}} \times 100
\]
- Where Net Benefits = Total Benefits - Total Costs.
4. **Consider Timeframe**:
- Determine the timeframe over which the ROI will be calculated, as benefits may accrue over time.
5. **Risk Assessment**:
- Evaluate the risks associated with implementing neural networks, including the potential for model failure, data quality issues, and the need for continuous monitoring and adjustment.
By following this framework, organizations can develop a comprehensive ROI calculation for implementing neural networks in supply chain optimization, even though the specific documents do not provide direct calculations or examples.
RELIABLE RAG:
------------------------------
Answer: I couldn't find relevant content in the document to answer your question.
Confidence: low
Validation: Failed
======================================================================
COMPARISON FOR NEURAL NETWORKS QUESTION: How do you handle numerical instability in very deep networks with 500+ layers?
======================================================================
TRADITIONAL RAG:
------------------------------
Handling numerical instability in very deep networks with 500+ layers involves several strategies:
1. **Gradient Normalization Techniques**: Implement techniques such as batch normalization, layer normalization, or group normalization. These methods help maintain appropriate gradient magnitudes throughout the network, mitigating issues like the vanishing and exploding gradient problems.
2. **Weight Initialization**: Use appropriate weight initialization methods such as Xavier (Glorot) initialization for sigmoid and tanh activations, or He initialization for ReLU activations. Proper initialization can prevent gradients from becoming too small or too large at the start of training.
3. **Gradient Clipping**: To address the exploding gradient problem, apply gradient clipping. This technique limits the maximum value of gradients during backpropagation, preventing them from growing excessively large and causing instability.
4. **Careful Learning Rate Scheduling**: Implement sophisticated learning rate scheduling strategies. Different layers may benefit from different learning rates, so using techniques like cyclical learning rates or adaptive learning rate methods (e.g., Adam, RMSprop) can help stabilize training.
5. **Use of Advanced Architectures**: Consider using architectures that are inherently more stable, such as residual networks (ResNets) or transformers, which are designed to facilitate training in very deep networks.
6. **Regularization Techniques**: Incorporate regularization methods such as dropout or weight decay to prevent overfitting and improve generalization, which can also contribute to numerical stability.
By combining these strategies, you can effectively manage numerical instability in very deep networks, ensuring more stable and efficient training.
RELIABLE RAG:
------------------------------
Answer: To handle numerical instability in very deep networks with 500+ layers, several strategies can be employed. First, utilize gradient normalization techniques such as batch normalization, layer normalization, or group normalization to maintain appropriate gradient magnitudes and mitigate the vanishing gradient problem. Additionally, implement careful weight initialization methods like Xavier or He initialization to prevent issues related to vanishing or exploding gradients. Finally, consider using gradient clipping to manage excessively large gradients and ensure stable training.
Confidence: high
Validation: Passed
Source Pages: 29, 29, 25
======================================================================
This comparison shows the key difference: traditional RAG might give confident answers about the content even when it shouldn’t, while Reliable RAG admits when it’s uncertain or when the question mixes unrelated concepts.
Free Course
Master Core Python — Your First Step into AI/ML
Build a strong Python foundation with hands-on exercises designed for aspiring Data Scientists and AI/ML Engineers.
Start Free Course →Trusted by 50,000+ learners
Related Course
Master Gen AI — Hands-On
Join 5,000+ students at edu.machinelearningplus.com
Explore Course

