14 min
14 min
Gen AI
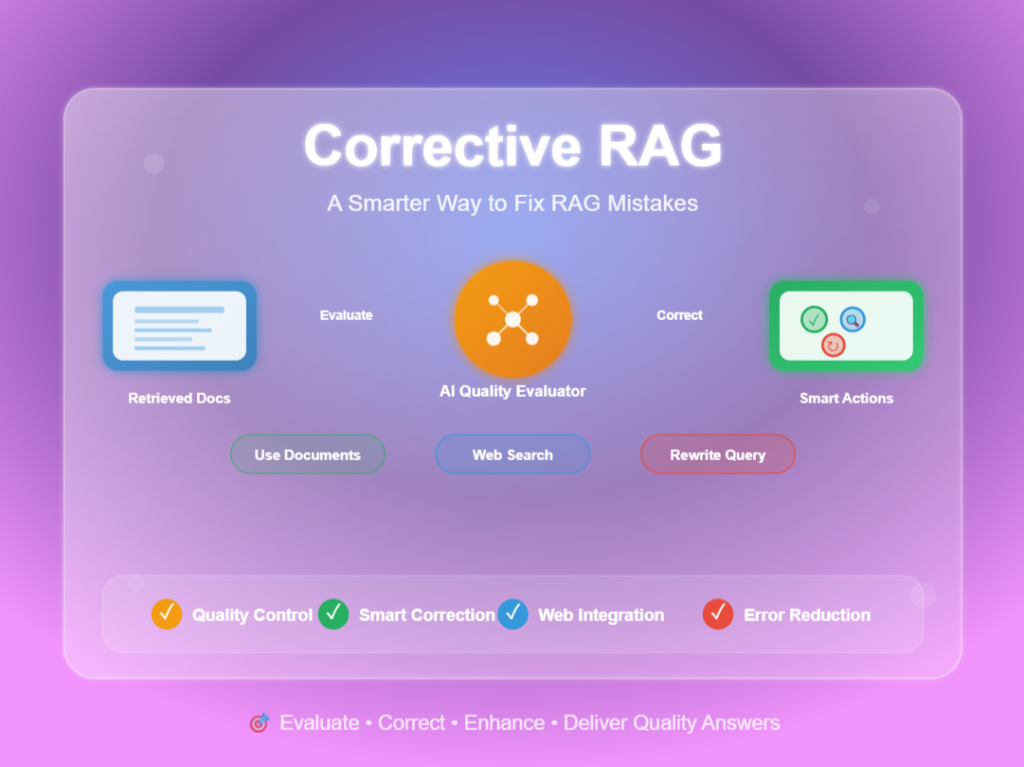
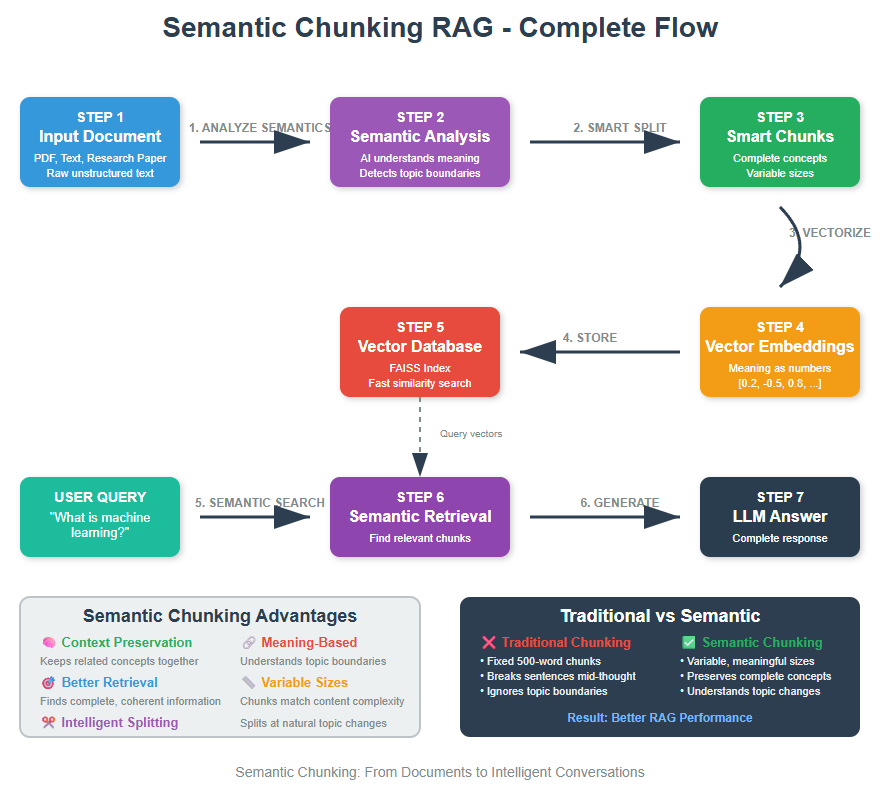
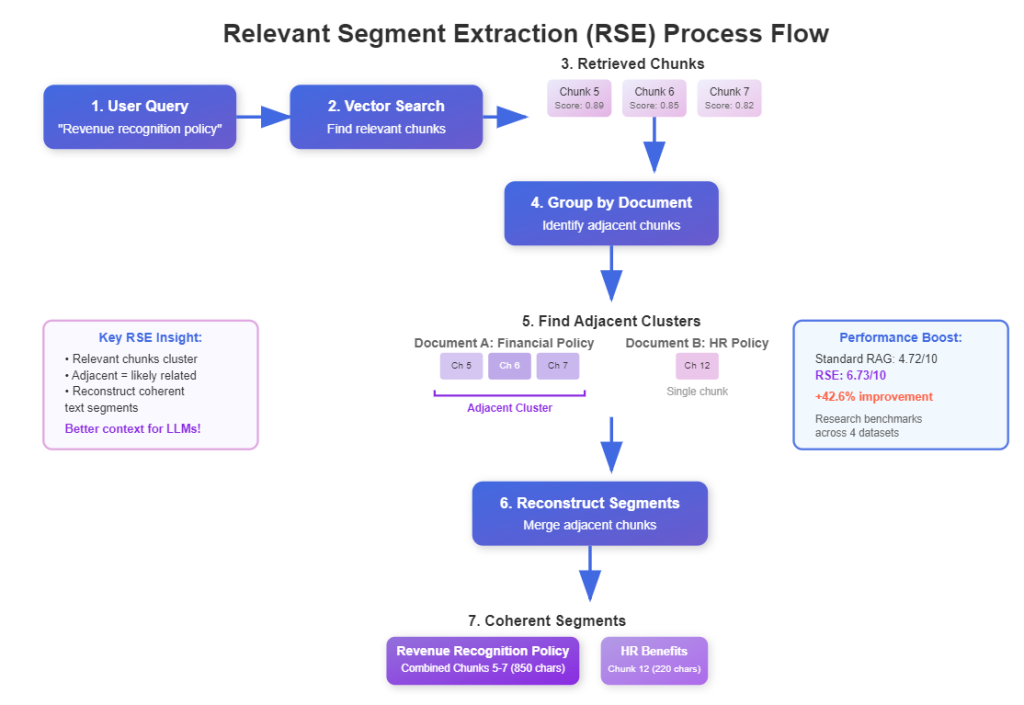
Feedback Loop RAG: Improving Retrieval with User Interactions
Feedback Loop RAG is an advanced RAG technique that learns from user interactions to continuously improve retrieval quality over time. Unlike traditional RAG systems...