machine learning +
LLM Temperature, Top-P, and Top-K Explained — With Python Simulations
Adaptive RAG: The Ultimate Guide to Dynamic Retrieval-Augmented Generation
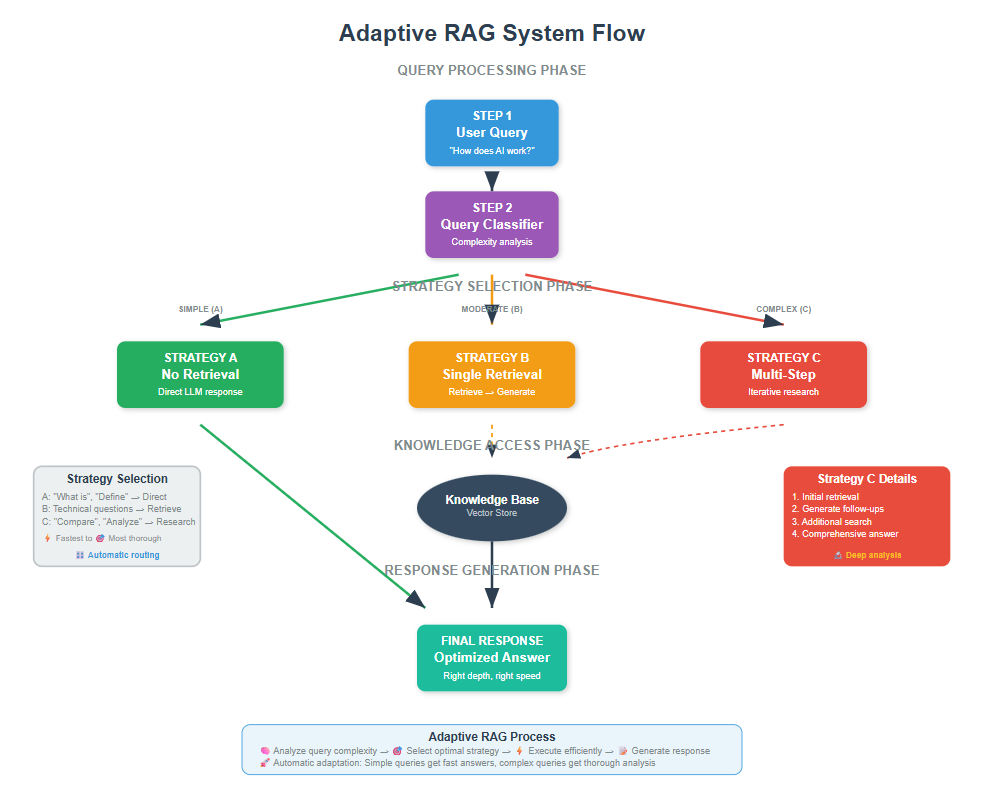
Adaptive RAG is a dynamic approach that automatically chooses the best retrieval strategy based on your question's complexity from no retrieval for simple queries to multistep retrieval for complex questions. Instead of using the same heavy approach for every question, it adapts like a smart assistant who knows when to look things up and when they already know the answer
Adaptive RAG is a dynamic approach that automatically chooses the best retrieval strategy based on your question’s complexity – from no retrieval for simple queries to multi-step retrieval for complex questions. Instead of using the same heavy approach for every question, it adapts like a smart assistant who knows when to look things up and when they already know the answer.
You know that feeling when you ask a simple question and wait forever for an answer? Or when you ask something complex and get a shallow response?
That’s exactly what Adaptive RAG solves.
It’s like having an intelligent assistant who knows when to dive deep and when to give you a quick answer.
Let me walk you through building your own Adaptive RAG system that gets smarter with every question.
1. Understanding the Problem We’re Solving
Regular RAG systems treat every question the same way. Whether you ask “What is Python?” or “How do distributed systems handle Byzantine failures in blockchain consensus mechanisms?”, they go through the same heavy retrieval process.
This creates two problems:
- Simple questions get unnecessarily slow and expensive processing
- Complex questions might not get the deep, multi-step reasoning they need
Adaptive RAG solves this by using a classifier to predict query complexity and dynamically selecting the most suitable strategy from simple to sophisticated approaches.
2. How Adaptive RAG Fixes the Problem
Researchers Soyeong Jeong, Jinheon Baek, Sukmin Cho, Sung Ju Hwang, and Jong Park solved this in their NAACL 2024 paper “Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity.” Their breakthrough was to automatically classify query complexity and dynamically select the right strategy.
Adaptive RAG chooses between three approaches:
1. No retrieval for simple factual questions the LLM already knows (“What is machine learning?”)
2. Single-step retrieval for moderate complexity questions (“How does OAuth2 work?”),
3. Multi-step retrieval for complex, multi-hop questions (“Compare caching strategies in microservices architectures”).
The system simply uses the right amount of effort for each question type, making it both faster and more accurate.
3. Setting Up Your Environment
Before we dive into the code, let’s get everything set up. I’ll assume you have Python and VS Code ready to go.
First, let’s install the packages we need:
bash
conda create -n rag python==3.12
conda activate rag
pip install ipykernel
pip install langchain openai faiss-cpu python-dotenv tiktoken transformers
Now let’s import everything:
python
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.vectorstores import FAISS
from langchain.prompts import PromptTemplate
from langchain.schema import Document
import numpy as np
# Load environment variables
load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv('OPENAI_API_KEY')
Quick note: Make sure you have a .env file with your OpenAI API key. It should look like this:
python
OPENAI_API_KEY=your_api_key_here
4. Loading and Processing Your Documents
For this tutorial, I’ll use a comprehensive PDF about AI and Machine Learning. Let’s load and process it.
You can download the pdf here
python
# Load the PDF document
pdf_path = "Artificial Intelligence.pdf" # Replace with your PDF path
pdf_loader = PyPDFLoader(pdf_path)
raw_documents = pdf_loader.load()
print(f"Loaded {len(raw_documents)} pages from the PDF")
print(f"First page preview: {raw_documents[0].page_content[:200]}...")
python
Loaded 14 pages from the PDF
First page preview: Artificial Intelligence and Machine Learning: Fundamentals,
Applications, and Future Directions
Introduction to Artificial Intelligence
Artificial Intelligence represents one of the most transformativ...
Note: Place your PDF file in the same directory as your notebook, or provide the full path to the file.
Now let’s chunk the documents properly
python
# Split the documents into manageable chunks
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # Larger chunks for better context
chunk_overlap=200, # Overlap to maintain context
separators=["\n\n", "\n", " ", ""]
)
# Split the documents into chunks
docs = text_splitter.split_documents(raw_documents)
print(f"Split {len(raw_documents)} pages into {len(docs)} chunks")
python
Split 14 pages into 57 chunks
This approach is more realistic since you’ll typically work with actual documents. The PDF contains rich content about AI fundamentals, machine learning, deep learning, and applications – perfect for testing our Adaptive RAG system.
5. Building the Document Store
Let’s create our vector store for retrieval
python
# Initialize embeddings model
embeddings = OpenAIEmbeddings()
# Create vector store
vectorstore = FAISS.from_documents(docs, embeddings)
# Create retriever
retriever = vectorstore.as_retriever(search_kwargs={"k": 2})
print("Vector store created successfully!")
python
Vector store created successfully!
6. Creating the Query Complexity Classifier
The main part of Adaptive RAG is the classifier that checks how complex a query is.Think of it as a smart traffic controller that decides which route your question should take.
In production, you’d train a machine learning model for this. But for learning purposes, we’ll build a rule-based classifier that’s easy to understand and modify.
Let’s start by defining our patterns. Simple questions usually begin with basic question words
python
# Simple factual questions (Strategy A - No Retrieval)
simple_patterns = [
"what is", "define", "who is", "when was", "where is",
"how do you", "what does", "basic", "simple"
]
Complex questions contain analytical keywords that suggest deep thinking
python
# Complex analytical questions (Strategy C - Multi-Step)
complex_patterns = [
"compare", "analyze", "evaluate", "trade-offs", "implications",
"advantages and disadvantages", "pros and cons", "performance",
"architecture", "design patterns", "best practices for"
]
Now let’s build our classifier logic. We check complex patterns first because they’re more specific
python
# Test query for demonstration
test_query = "Compare the ethical implications of AI in healthcare versus autonomous vehicles"
query_lower = test_query.lower()
print(f"Original query: {test_query}")
print(f"Lowercase query: {query_lower}")
# Check for complex patterns first
complexity = None
if any(pattern in query_lower for pattern in complex_patterns):
complexity = 'C'
print("Found complex pattern - assigning Strategy C")
elif any(pattern in query_lower for pattern in simple_patterns):
complexity = 'A'
print("Found simple pattern - assigning Strategy A")
else:
complexity = 'B'
print("No specific pattern found - assigning Strategy B (default)")
print(f"Final complexity: {complexity}")
python
Original query: Compare the ethical implications of AI in healthcare versus autonomous vehicles
Lowercase query: compare the ethical implications of ai in healthcare versus autonomous vehicles
Found complex pattern - assigning Strategy C
Final complexity: C
Why this approach works:
- Simple questions seek basic definitions or facts
- Complex questions involve analysis, comparison, or evaluation
- Everything else falls into moderate complexity
This pattern-based approach is surprisingly effective and easy to customize for your domain.
7. Implementing Strategy A: No Retrieval
Strategy A is the simplest approach – we ask the LLM directly without any document retrieval. This works well for questions the model already knows from its training.
Let’s set up our language model first and implement Strategy A
python
# Initialize our language model
llm = ChatOpenAI(temperature=0, model_name="gpt-4o-mini")
print("Language model initialized successfully!")
# Test query for Strategy A
simple_query = "What is artificial intelligence?"
# Create a basic prompt template
prompt_template = "Answer this question directly using your knowledge: {query}"
formatted_prompt = prompt_template.format(query=simple_query)
print("Formatted prompt:")
print(formatted_prompt)
print("\n" + "="*50)
# Get response from LLM
response = llm.invoke([{"role": "user", "content": formatted_prompt}])
strategy_a_result = {
"answer": response.content,
"strategy": "A (No Retrieval)",
"retrieved_docs": [],
"query": simple_query
}
print("Strategy A Response:")
print(strategy_a_result["answer"])
python
Language model initialized successfully!
Formatted prompt:
Answer this question directly using your knowledge: What is artificial intelligence?
==================================================
Strategy A Response:
Artificial intelligence (AI) is a branch of computer science focused on creating systems and technologies that can perform tasks typically requiring human intelligence. These tasks include problem-solving, learning, reasoning, understanding natural language, recognizing patterns, and making decisions. AI can be categorized into two main types: narrow AI, which is designed for specific tasks (like virtual assistants or recommendation systems), and general AI, which aims to replicate human cognitive abilities across a wide range of activities. AI technologies often utilize machine learning, deep learning, and neural networks to improve their performance over time.
8. Implementing Strategy B: Single-Step Retrieval
Strategy B retrieves relevant documents once and uses them to answer the question. This balances efficiency with access to external knowledge.
Let’s see how the retrieval works
python
# Test query for Strategy B
moderate_query = "How does deep learning work in computer vision?"
# Retrieve relevant documents
print(f"Searching for documents related to: '{moderate_query}'")
retrieved_docs = retriever.invoke(moderate_query)
print(f"Found {len(retrieved_docs)} relevant documents")
print("\nFirst document preview:")
print(retrieved_docs[0].page_content[:300] + "...")
python
Searching for documents related to: 'How does deep learning work in computer vision?'
Found 2 relevant documents
First document preview:
for image classification tasks. The development of the bag-of-words model for computer vision,
inspired by techniques from natural language processing, enabled more sophisticated approaches
to image categorization. Researchers like Antonio Torralba and Aude Oliva made significant
contributions to sc...
Now let’s combine the retrieved content with our query
python
# Combine all retrieved documents into context
context_parts = []
for i, doc in enumerate(retrieved_docs):
context_parts.append(f"Document {i+1}:\n{doc.page_content}")
full_context = "\n\n".join(context_parts)
print("Combined context length:", len(full_context))
print("\nContext preview:")
print(full_context[:400] + "...")
python
Combined context length: 1919
Context preview:
Document 1:
for image classification tasks. The development of the bag-of-words model for computer vision,
inspired by techniques from natural language processing, enabled more sophisticated approaches
to image categorization. Researchers like Antonio Torralba and Aude Oliva made significant
contributions to scene understanding and the recognition of object categories in natural images.
The deep l...
Multiple documents often contain complementary information that together provide a complete answer.
Now let’s create a prompt that uses both context and query and retrieve the response
python
# Create context-aware prompt
context_prompt_template = """Based on the following context, answer the question:
Context:
{context}
Question: {query}
Answer:"""
formatted_context_prompt = context_prompt_template.format(
context=full_context,
query=moderate_query
)
# Get response using context
response = llm.invoke([{"role": "user", "content": formatted_context_prompt}])
strategy_b_result = {
"answer": response.content,
"strategy": "B (Single Retrieval)",
"retrieved_docs": retrieved_docs,
"query": moderate_query
}
print("Strategy B Response:")
print(strategy_b_result["answer"])
print(f"\nUsed {len(retrieved_docs)} documents for context")
python
Strategy B Response:
Deep learning in computer vision primarily utilizes Convolutional Neural Networks (CNNs), which are designed to automatically learn hierarchical features from images. The process begins with the input image being passed through multiple layers of convolutional filters that detect various features, such as edges, textures, and shapes. These features are progressively combined and abstracted through additional layers, allowing the network to learn complex patterns and representations.
The architecture of CNNs typically includes convolutional layers, pooling layers, and fully connected layers. Convolutional layers apply filters to the input image to extract features, pooling layers reduce the spatial dimensions of the feature maps, and fully connected layers make final classifications based on the learned features.
The breakthrough in deep learning for computer vision was marked by the success of the AlexNet architecture in 2012, which significantly outperformed traditional methods in image classification tasks. This success led to the widespread adoption of deep learning techniques in the field. Subsequent architectures, such as VGGNet and ResNet, have further advanced the capabilities of CNNs by exploring deeper networks and innovative designs, pushing the boundaries of performance in image analysis. Overall, deep learning mimics the hierarchical structure of the visual cortex, making it particularly effective for visual tasks.
Used 2 documents for context
9. Implementing Strategy C: Multi-Step Retrieval
Strategy C is the most sophisticated approach. It performs multiple rounds of retrieval and analysis to handle complex questions that require deep investigation.
Let’s work through this with a complex query
python
# Test query for Strategy C
complex_query = "Compare the ethical implications of AI across different industries"
Step 1: Initial Retrieval
Start with a basic retrieval to get some initial context
python
# Step 1: Get initial documents
print("Step 1: Initial retrieval...")
initial_docs = retriever.get_relevant_documents(complex_query)
all_retrieved_docs = initial_docs.copy() # Track all documents
print(f"Retrieved {len(initial_docs)} initial documents")
# Show what we found
for i, doc in enumerate(initial_docs):
print(f"Doc {i+1} preview: {doc.page_content[:150]}...")
print("-" * 40)
python
Step 1: Initial retrieval...
Retrieved 2 initial documents
Doc 1 preview: field of AI ethics has emerged as a critical discipline that seeks to ensure that AI development and
deployment align with human values and societal w...
----------------------------------------
Doc 2 preview: As we look toward the future, the responsible development and deployment of AI technologies will
require ongoing collaboration between technologists, ...
----------------------------------------
Step 2: Generate Follow-up Questions
Complex queries often need multiple perspectives. Let’s ask the LLM what additional information would help
python
# Step 2: Generate follow-up questions for deeper analysis
print("\nStep 2: Generating follow-up questions...")
initial_context = "\n\n".join([doc.page_content for doc in initial_docs])
followup_prompt_template = """Based on this context and query, generate 1-2 specific follow-up questions that would help provide a more comprehensive answer:
Context: {context}
Original Query: {query}
Follow-up questions (one per line):"""
formatted_followup_prompt = followup_prompt_template.format(
context=initial_context,
query=complex_query
)
# Get follow-up questions
followup_response = llm.invoke([{"role": "user", "content": formatted_followup_prompt}])
print("Follow-up questions generated:")
print(followup_response.content)
# Parse the questions
followup_questions = [q.strip() for q in followup_response.content.split('\n') if q.strip()]
print(f"\nParsed {len(followup_questions)} follow-up questions")
python
Step 2: Generating follow-up questions...
Follow-up questions generated:
What specific industries have been most affected by algorithmic bias, and what measures are being taken to address these ethical implications?
How do the ethical considerations of AI in healthcare differ from those in finance or law enforcement?
Parsed 2 follow-up questions
Step 3: Retrieve for Follow-up Questions
Now we’ll search for documents that answer our follow-up questions
python
# Step 3: Retrieve documents for each follow-up question
print("\nStep 3: Retrieving for follow-up questions...")
for i, followup_q in enumerate(followup_questions[:2]): # Limit to 2 for efficiency
print(f"\nFollow-up {i+1}: {followup_q}")
additional_docs = retriever.get_relevant_documents(followup_q)
all_retrieved_docs.extend(additional_docs)
print(f"Found {len(additional_docs)} additional documents")
# Show preview of new documents
for j, doc in enumerate(additional_docs):
print(f" New doc {j+1}: {doc.page_content[:100]}...")
print(f"\nTotal documents collected: {len(all_retrieved_docs)}")
python
Step 3: Retrieving for follow-up questions...
Follow-up 1: What specific industries have been most affected by algorithmic bias, and what measures are being taken to address these ethical implications?
Found 2 additional documents
New doc 1: field of AI ethics has emerged as a critical discipline that seeks to ensure that AI development and...
New doc 2: The work of researchers like Cathy O'Neil, author of "Weapons of Math Destruction," has drawn
attent...
Follow-up 2: How do the ethical considerations of AI in healthcare differ from those in finance or law enforcement?
Found 2 additional documents
New doc 1: Researchers like Moritz Hardt at UC Berkeley and Solon Barocas at Cornell University have
contribute...
New doc 2: As we look toward the future, the responsible development and deployment of AI technologies will
req...
Total documents collected: 6
Step 4: Generate Comprehensive Answer
Finally, we use all collected information to provide a thorough response
python
# Step 4: Generate comprehensive answer using all context
print("\nStep 4: Generating comprehensive answer...")
# Combine all retrieved documents
all_context = "\n\n".join([doc.page_content for doc in all_retrieved_docs])
final_prompt_template = """Based on the comprehensive context below, provide a detailed analysis answering the question:
Context:
{context}
Question: {query}
Provide a thorough answer that considers multiple aspects:"""
formatted_final_prompt = final_prompt_template.format(
context=all_context,
query=complex_query
)
# Get final comprehensive response
final_response = llm.invoke([{"role": "user", "content": formatted_final_prompt}])
strategy_c_result = {
"answer": final_response.content,
"strategy": "C (Multi-Step Retrieval)",
"retrieved_docs": all_retrieved_docs,
"followup_questions": followup_questions,
"query": complex_query
}
print("Strategy C Response:")
print(strategy_c_result["answer"])
print(f"\nUsed {len(all_retrieved_docs)} total documents")
print(f"Generated {len(followup_questions)} follow-up questions")
python
Step 4: Generating comprehensive answer...
Strategy C Response:
The ethical implications of artificial intelligence (AI) vary significantly across different industries, influenced by the specific contexts in which AI technologies are deployed, the potential consequences of their use, and the societal values at stake. Below is a detailed analysis of the ethical implications of AI across several key industries, including healthcare, criminal justice, finance, and hiring.
### 1. Healthcare
**Ethical Implications:**
- **Algorithmic Bias:** AI systems in healthcare can perpetuate biases present in training data, leading to unequal treatment outcomes. For instance, if a dataset predominantly includes data from one demographic group, the AI may not perform well for underrepresented groups, potentially exacerbating health disparities.
- **Transparency and Explainability:** The use of AI in diagnostic tools raises concerns about the "black box" nature of these systems. Patients and healthcare providers need to understand how decisions are made, especially when they affect treatment options. Lack of transparency can undermine trust in AI systems.
- **Informed Consent:** The integration of AI in patient care necessitates clear communication about how AI tools are used in diagnosis and treatment. Patients must be informed about the role of AI in their care and provide consent for its use.
- **Data Privacy:** The sensitive nature of health data raises significant privacy concerns. Ensuring that patient data is protected while still allowing for the development of effective AI tools is a critical ethical challenge.
### 2. Criminal Justice
**Ethical Implications:**
- **Discriminatory Outcomes:** AI systems used in predictive policing or risk assessment tools can reinforce existing biases in the criminal justice system. For example, if historical crime data reflects systemic biases against certain racial or socioeconomic groups, AI systems may unfairly target these communities.
- **Accountability:** The use of AI in criminal justice raises questions about accountability. If an AI system makes a flawed prediction that leads to wrongful arrests or sentencing, it is unclear who is responsible—the developers, the law enforcement agencies, or the AI itself?
- **Transparency:** Similar to healthcare, the opacity of AI algorithms in criminal justice can lead to a lack of trust. Stakeholders, including defendants and their legal representatives, need to understand how decisions are made to ensure fair treatment.
- **Impact on Civil Liberties:** The deployment of AI in surveillance and monitoring can infringe on individual rights and freedoms, raising ethical concerns about privacy and the potential for abuse of power.
### 3. Finance
**Ethical Implications:**
- **Algorithmic Bias:** In finance, AI systems used for credit scoring or loan approvals can inadvertently discriminate against marginalized groups if the training data reflects historical inequalities. This can lead to unequal access to financial services.
- **Transparency and Explainability:** Financial decisions made by AI systems can have significant consequences for individuals and businesses. Stakeholders need to understand how these decisions are made to ensure fairness and accountability.
- **Data Privacy:** The financial sector handles sensitive personal information, making data privacy a paramount concern. Ethical AI development must prioritize the protection of consumer data while leveraging it for predictive analytics.
- **Market Manipulation:** The use of AI in trading and investment raises ethical questions about market fairness. High-frequency trading algorithms can create an uneven playing field, favoring those with access to advanced technology.
### 4. Hiring and Employment
**Ethical Implications:**
- **Bias in Hiring Algorithms:** AI systems used for recruitment can perpetuate gender, racial, and socioeconomic biases if they are trained on biased historical data. This can lead to discriminatory hiring practices, as seen in the case of Amazon's hiring algorithm.
- **Transparency and Fairness:** Candidates have a right to understand how AI systems evaluate their applications. Lack of transparency can lead to mistrust and feelings of unfairness among job seekers.
- **Impact on Workforce Diversity:** The use of biased AI in hiring can hinder efforts to promote diversity and inclusion in the workplace. Organizations must be vigilant in ensuring that AI tools do not reinforce existing inequalities.
- **Job Displacement:** As AI automates certain tasks, ethical considerations arise regarding the impact on employment. Organizations must consider the societal implications of job displacement and invest in workforce development and retraining programs.
### Conclusion
The ethical implications of AI are multifaceted and vary across industries, reflecting the unique challenges and societal values at play. Addressing these ethical concerns requires a collaborative approach involving technologists, ethicists, policymakers, and civil society organizations. As AI technologies continue to evolve and permeate various sectors, ongoing dialogue and proactive measures will be essential to ensure that AI development aligns with human values and promotes societal well-being. This includes fostering transparency, accountability, and fairness in AI systems, as well as prioritizing equitable access to the benefits of AI across diverse communities.
Used 6 total documents
Generated 2 follow-up questions
The power of Strategy C is that it uses multiple retrieval rounds and follow-up questions to gather detailed, well-rounded information, making it ideal for complex analysis and comparison tasks.
10. Building the Complete Adaptive RAG System
Now let’s combine all three strategies into one system that picks the best approach for each question.
First let’s build the main adaptive system that routes queries to the appropriate strategy
python
def adaptive_rag(query):
"""
Complete Adaptive RAG function that automatically selects the best strategy
based on query complexity and processes the query accordingly.
Args:
query (str): The user's question
Returns:
dict: Result containing answer, strategy used, retrieved docs, etc.
"""
print(f"Processing query: {query}")
# Step 1: Classify query complexity
query_lower = query.lower()
if any(pattern in query_lower for pattern in complex_patterns):
complexity = 'C'
reasoning = "Contains complex analysis patterns"
elif any(pattern in query_lower for pattern in simple_patterns):
complexity = 'A'
reasoning = "Contains simple question patterns"
else:
complexity = 'B'
reasoning = "Default moderate complexity"
print(f"Detected complexity: {complexity} ({reasoning})")
# Step 2: Route to appropriate strategy and process
if complexity == 'A':
# Strategy A: Direct LLM response
print("Using Strategy A: No Retrieval")
prompt = f"Answer this question directly using your knowledge: {query}"
response = llm.invoke([{"role": "user", "content": prompt}])
result = {
"answer": response.content,
"strategy": "A (No Retrieval)",
"retrieved_docs": [],
"query": query,
"complexity": complexity
}
elif complexity == 'B':
# Strategy B: Single retrieval
print("Using Strategy B: Single Retrieval")
docs = retriever.get_relevant_documents(query)
context = "\n\n".join([doc.page_content for doc in docs])
prompt = f"""Based on the following context, answer the question:
Context:
{context}
Question: {query}
Answer:"""
response = llm.invoke([{"role": "user", "content": prompt}])
result = {
"answer": response.content,
"strategy": "B (Single Retrieval)",
"retrieved_docs": docs,
"query": query,
"complexity": complexity
}
else: # complexity == 'C'
# Strategy C: Multi-step retrieval
print("Using Strategy C: Multi-Step Retrieval")
# Step 1: Initial retrieval
initial_docs = retriever.get_relevant_documents(query)
initial_context = "\n\n".join([doc.page_content for doc in initial_docs])
# Step 2: Generate follow-up questions
followup_prompt = f"""Based on this context and query, generate 1-2 specific follow-up questions that would help provide a more comprehensive answer:
Context: {initial_context}
Original Query: {query}
Follow-up questions (one per line):"""
followup_response = llm.invoke([{"role": "user", "content": followup_prompt}])
followup_questions = [q.strip() for q in followup_response.content.split('\n') if q.strip()]
# Step 3: Retrieve for follow-up questions
all_docs = initial_docs.copy()
for followup_q in followup_questions[:2]: # Limit to 2
additional_docs = retriever.get_relevant_documents(followup_q)
all_docs.extend(additional_docs)
# Step 4: Generate comprehensive answer
comprehensive_context = "\n\n".join([doc.page_content for doc in all_docs])
final_prompt = f"""Based on the comprehensive context below, provide a detailed analysis answering the question:
Context:
{comprehensive_context}
Question: {query}
Provide a thorough answer that considers multiple aspects:"""
response = llm.invoke([{"role": "user", "content": final_prompt}])
result = {
"answer": response.content,
"strategy": "C (Multi-Step Retrieval)",
"retrieved_docs": all_docs,
"followup_questions": followup_questions,
"query": query,
"complexity": complexity
}
return result
print("Adaptive RAG function created successfully!")
python
Adaptive RAG function created successfully!
Let’s also create a helper function to display results nicely
python
def display_result(result):
"""
Helper function to display Adaptive RAG results in a clean format
"""
print("\n" + "="*60)
print(f"QUERY: {result['query']}")
print(f"COMPLEXITY: {result['complexity']}")
print(f"STRATEGY: {result['strategy']}")
print("\nANSWER:")
print(result['answer'])
if result['retrieved_docs']:
print(f"\nRETRIEVED {len(result['retrieved_docs'])} DOCUMENTS")
if 'followup_questions' in result:
print(f"\nFOLLOW-UP QUESTIONS GENERATED:")
for i, q in enumerate(result['followup_questions'], 1):
print(f" {i}. {q}")
print("="*60)
print("Display function created successfully!")
python
Display function created successfully!
11. Testing the Adaptive System
Let’s test our system with different types of questions based on our content
python
# Test queries of different complexities
test_queries = [
"What is artificial intelligence?", # Should use Strategy A - simple definition
"How does deep learning work?", # Should use Strategy B - moderate complexity
"Compare the advantages and disadvantages of different machine learning paradigms in healthcare applications" # Should use Strategy C - complex analysis
]
# Run each query through our adaptive system
for query in test_queries:
result = adaptive_rag(query)
display_result(result)
print("\n")
python
Processing query: What is artificial intelligence?
Detected complexity: A (Contains simple question patterns)
Using Strategy A: No Retrieval
============================================================
QUERY: What is artificial intelligence?
COMPLEXITY: A
STRATEGY: A (No Retrieval)
ANSWER:
Artificial intelligence (AI) is a branch of computer science focused on creating systems or machines that can perform tasks typically requiring human intelligence. These tasks include problem-solving, learning, reasoning, understanding natural language, recognizing patterns, and making decisions. AI can be categorized into two main types: narrow AI, which is designed for specific tasks (like virtual assistants or recommendation systems), and general AI, which aims to replicate human cognitive abilities across a wide range of activities. AI technologies often involve machine learning, deep learning, and neural networks to improve performance and adapt to new data.
============================================================
Processing query: How does deep learning work?
Detected complexity: B (Default moderate complexity)
Using Strategy B: Single Retrieval
============================================================
QUERY: How does deep learning work?
COMPLEXITY: B
STRATEGY: B (Single Retrieval)
ANSWER:
Deep learning works by utilizing artificial neural networks that consist of multiple layers to model and understand complex patterns in data. These networks are inspired by the structure and function of the human brain, where interconnected neurons process information.
In a typical deep learning model, data is fed into the input layer of the neural network, which then passes through one or more hidden layers. Each layer consists of numerous neurons that apply mathematical transformations to the input data. The connections between neurons have associated weights that are adjusted during the training process to minimize the difference between the predicted output and the actual output (known as the loss).
The training process involves using large datasets and optimization algorithms, such as stochastic gradient descent, to iteratively update the weights based on the error calculated from the predictions. This allows the network to learn complex representations and features from the data.
Deep learning has been particularly successful in tasks such as image recognition, natural language processing, and game playing, as it can automatically extract relevant features from raw data without the need for manual feature engineering. The use of multiple layers enables the model to learn hierarchical representations, where lower layers capture simple patterns and higher layers capture more abstract concepts. This capability has led to significant advancements in various AI applications.
RETRIEVED 2 DOCUMENTS
============================================================
Processing query: Compare the advantages and disadvantages of different machine learning paradigms in healthcare applications
Detected complexity: C (Contains complex analysis patterns)
Using Strategy C: Multi-Step Retrieval
============================================================
QUERY: Compare the advantages and disadvantages of different machine learning paradigms in healthcare applications
COMPLEXITY: C
STRATEGY: C (Multi-Step Retrieval)
ANSWER:
Machine learning (ML) paradigms—supervised learning, unsupervised learning, and reinforcement learning—each have unique advantages and disadvantages when applied to healthcare applications. Understanding these can help stakeholders make informed decisions about which approach to use in specific contexts.
### Supervised Learning
**Advantages:**
1. **High Accuracy**: Supervised learning algorithms, trained on labeled datasets, can achieve high accuracy in tasks such as classification and regression. For instance, AI systems for diagnosing diseases from medical images (e.g., mammography for breast cancer) have shown performance levels comparable to expert radiologists.
2. **Clear Interpretability**: Many supervised learning models, such as decision trees, provide clear decision paths, making it easier for clinicians to understand the rationale behind predictions. This interpretability is crucial in healthcare, where decisions can significantly impact patient outcomes.
3. **Robustness**: Supervised learning models can be fine-tuned and validated using cross-validation techniques, leading to robust performance in real-world applications. This is particularly important in healthcare, where data can be noisy and complex.
**Disadvantages:**
1. **Data Dependency**: Supervised learning requires large amounts of labeled data, which can be challenging to obtain in healthcare due to privacy concerns, the need for expert annotation, and the variability in data quality.
2. **Overfitting**: There is a risk of overfitting the model to the training data, especially if the dataset is small or not representative of the broader population. This can lead to poor generalization in clinical settings.
3. **Limited Flexibility**: Supervised learning is typically designed for specific tasks, which may limit its adaptability to new or unforeseen healthcare challenges.
### Unsupervised Learning
**Advantages:**
1. **Pattern Discovery**: Unsupervised learning excels at identifying hidden patterns and structures in data without the need for labeled examples. This can be particularly useful in exploratory data analysis, such as identifying subtypes of diseases or patient clusters.
2. **Data Efficiency**: It can work with unlabeled data, which is often more abundant in healthcare settings. This allows for the analysis of large datasets without the need for extensive labeling efforts.
3. **Feature Extraction**: Unsupervised learning can help in feature extraction, which can enhance the performance of supervised models by identifying relevant variables that may not be immediately apparent.
**Disadvantages:**
1. **Interpretability Challenges**: The results of unsupervised learning can be difficult to interpret, making it challenging for clinicians to derive actionable insights. For example, clustering algorithms may identify patient groups, but the clinical significance of these groups may not be clear.
2. **Lack of Predictive Power**: Unlike supervised learning, unsupervised learning does not provide direct predictions or classifications, which can limit its immediate applicability in clinical decision-making.
3. **Risk of Misinterpretation**: The absence of labeled data can lead to misinterpretation of the results, as the model may identify patterns that are not clinically relevant or meaningful.
### Reinforcement Learning
**Advantages:**
1. **Dynamic Decision-Making**: Reinforcement learning (RL) is particularly suited for dynamic environments where decisions need to be made sequentially over time, such as in treatment planning or personalized medicine. It can adapt to changing patient conditions and optimize treatment strategies.
2. **Learning from Interaction**: RL algorithms learn from interactions with the environment, allowing them to improve over time based on feedback. This can lead to more personalized and effective treatment recommendations.
3. **Complex Problem Solving**: RL can handle complex problems with multiple variables and outcomes, making it suitable for applications like optimizing resource allocation in healthcare systems.
**Disadvantages:**
1. **Data Requirements**: RL often requires a large amount of interaction data to learn effectively, which can be difficult to obtain in healthcare settings where patient interactions are limited or costly.
2. **Computational Complexity**: The algorithms can be computationally intensive and may require significant resources, making them less accessible for smaller healthcare organizations.
3. **Ethical Concerns**: The use of RL in healthcare raises ethical concerns, particularly regarding patient safety and the potential for unintended consequences from suboptimal decision-making during the learning phase.
### Conclusion
In summary, each machine learning paradigm offers distinct advantages and disadvantages in healthcare applications. Supervised learning is powerful for tasks requiring high accuracy and interpretability but is limited by data availability and the risk of overfitting. Unsupervised learning excels at discovering patterns in unlabeled data but struggles with interpretability and direct applicability. Reinforcement learning offers dynamic decision-making capabilities but faces challenges related to data requirements and ethical considerations. The choice of paradigm should be guided by the specific healthcare context, the nature of the data available, and the desired outcomes.
RETRIEVED 6 DOCUMENTS
FOLLOW-UP QUESTIONS GENERATED:
1. 1. What specific machine learning paradigms are currently being utilized in healthcare applications, and how do their advantages and disadvantages differ in terms of data requirements and interpretability?
2. 2. Can you provide examples of successful healthcare applications for each machine learning paradigm, highlighting the outcomes and challenges faced in their implementation?
============================================================
Watch how the system adapts its approach based on each question’s complexity.
The simple definition question gets answered directly from the LLM’s knowledge, the moderate question triggers single-step retrieval, and the complex comparison question initiates multi-step iterative retrieval.
Free Course
Master Core Python — Your First Step into AI/ML
Build a strong Python foundation with hands-on exercises designed for aspiring Data Scientists and AI/ML Engineers.
Start Free Course →Trusted by 50,000+ learners
Related Course
Master Gen AI — Hands-On
Join 5,000+ students at edu.machinelearningplus.com
Explore Course

