machine learning +
LLM Temperature, Top-P, and Top-K Explained — With Python Simulations
Document Augmentation : A Guide to Optimizing RAG Performance
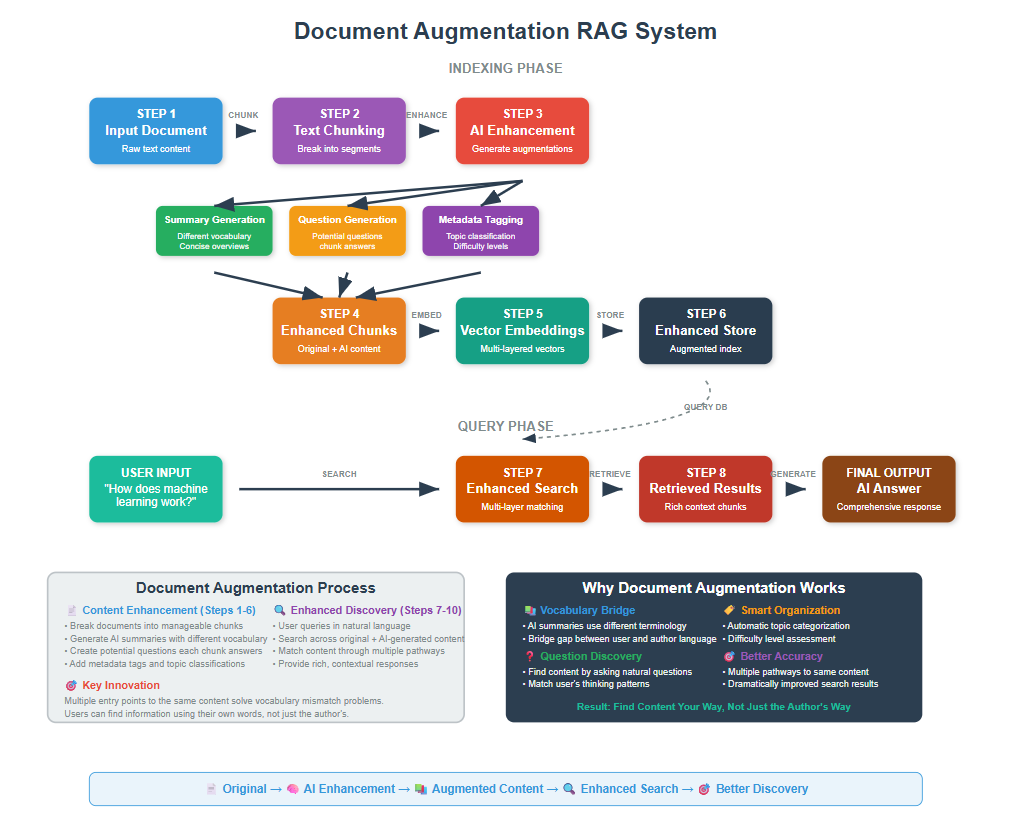
Document Augmentation RAG is an advanced retrieval technique that enhances original documents by automatically generating additional context, summaries, questions, and metadata before indexing them for search. This approach dramatically improves search accuracy by creating multiple entry points and enriched content that matches user queries better
Document Augmentation RAG is an advanced retrieval technique that enhances original documents by automatically generating additional context, summaries, questions, and metadata before indexing them for search. This approach dramatically improves search accuracy by creating multiple entry points and enriched content that matches user queries better.
Have you ever searched your document collection and missed relevant content because you used different words than the author? Or struggled to find information because the document didn’t contain the exact terms you searched for?
Traditional RAG systems only search the original document text, which creates a vocabulary mismatch problem.
Document Augmentation RAG solves this by enriching your documents.
It adds summaries, generates potential questions the document answers, creates topic tags, and builds contextual metadata. This gives you multiple ways to find the same information.
By the end, you’ll have a document augmentation pipeline that makes your content much easier to find.
1. The Problem We’re Solving
Document Augmentation RAG improves the chance of retrieving the appropriate context data by enhancing the context with additional data.
It does this by creating multiple representations of the same content:
- Original text + AI-generated summary
- Original content + potential questions it answers
- Basic text + topic tags and metadata
- Core information + expanded explanations
This gives your search system many more ways to match user queries with relevant content.
2. Setting Up Your Environment
Let’s get your development environment ready. I’ll assume you have Python and VS Code set up.
First install the packages we need:
bash
conda create -n rag python==3.12
conda activate rag
pip install ipykernel
pip install langchain openai faiss-cpu python-dotenv tiktoken pypdf
pip install sentence-transformers
Now let’s import everything we need:
python
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.vectorstores import FAISS
from langchain.prompts import PromptTemplate
from langchain.schema import Document
import textwrap
import json
from typing import List, Dict
import time
# Load environment variables
load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv('OPENAI_API_KEY')
Make sure you have a .env file with your OpenAI API key:
python
OPENAI_API_KEY=your_api_key_here
3. Loading and Processing Your Documents
Let’s start by loading a PDF document and splitting it into chunks. We’ll use a document on Neural Networks as our example.
You can download the pdf here
python
# Load the PDF document
document_path = "Neural Networks.pdf"
pdf_loader = PyPDFLoader(document_path)
raw_documents = pdf_loader.load()
print(f"Loaded {len(raw_documents)} pages from the PDF")
print(f"First page preview: {raw_documents[0].page_content[:200]}...")
python
Loaded 51 pages from the PDF
First page preview: Comprehensive Guide to Neural Networks
Table of Contents
1. Introduction to Neural Networks
2. Historical Development and Evolution
3. Mathematical Foundations
4. Basic Neural Network Architecture
5. ...
Now let’s split the document into manageable chunks. We’ll use slightly larger chunks since we’ll be adding content to them
python
# Configure text splitter for document augmentation
chunk_size = 800 # Larger chunks for better context
chunk_overlap = 150 # Good overlap for continuity
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
separators=["\n\n", "\n", ". ", " ", ""]
)
# Split documents into chunks
document_chunks = text_splitter.split_documents(raw_documents)
print(f"Split {len(raw_documents)} pages into {len(document_chunks)} chunks")
python
Split 51 pages into 217 chunks
We use larger chunks (800 characters) because we’ll be adding augmented content to each chunk. This gives us better context for AI generation while keeping chunks manageable.
4. Setting Up AI Models for Augmentation
Now let’s set up the AI models we’ll use to augment our documents
python
# Initialize language model for content generation
llm = ChatOpenAI(
temperature=0.3, # Slightly creative for varied augmentations
model_name="gpt-4",
max_tokens=500
)
print("Language model initialized for document augmentation")
python
Language model initialized for document augmentation
The temperature of 0.3 gives us consistent but slightly varied responses, which is perfect for generating diverse augmentations of the same content.
5.Creating Document Summaries
Let’s create our first augmentation: AI-generated summaries. These provide high-level overviews that might match user queries better than the detailed original text.
python
def generate_document_summary(text_chunk):
"""
Generate a concise summary of a document chunk
"""
summary_prompt = PromptTemplate(
input_variables=["text"],
template="""Create a concise summary of the following text. Focus on the main concepts, key points, and important information. Keep it clear and searchable.
Text:
{text}
Summary:"""
)
summary_chain = summary_prompt | llm
response = summary_chain.invoke({"text": text_chunk})
return response.content.strip()
# Test summary generation
test_chunk = document_chunks[0].page_content
test_summary = generate_document_summary(test_chunk)
print("Original chunk:")
print("-" * 50)
print(test_chunk[:300])
print("\nGenerated summary:")
print("-" * 50)
print(test_summary)
python
Original chunk:
--------------------------------------------------
Comprehensive Guide to Neural Networks
Table of Contents
1. Introduction to Neural Networks
2. Historical Development and Evolution
3. Mathematical Foundations
4. Basic Neural Network Architecture
5. Learning Algorithms and Training
6. Activation Functions and Optimization
7. Deep Learning and Deep
Generated summary:
--------------------------------------------------
The text is a comprehensive guide to neural networks, covering topics from introduction, historical development, mathematical foundations, and basic architecture, to learning algorithms, activation functions, deep learning, convolutional and recurrent networks, advanced architectures, training techniques, applications, tools, frameworks, challenges, limitations, and future prospects. It provides an in-depth understanding of neural networks, a significant breakthrough in artificial intelligence.
This function takes a document chunk and creates a summary that captures the main ideas in different words. This helps bridge vocabulary gaps between authors and searchers.
6. Generating Potential Questions
Now let’s create our second augmentation: potential questions that each chunk answers. This is powerful because users often search by asking questions.
python
def generate_potential_questions(text_chunk):
"""
Generate questions that this document chunk could answer
"""
questions_prompt = PromptTemplate(
input_variables=["text"],
template="""Based on the following text, generate 3-5 specific questions that this content directly answers. Make the questions natural and varied - the way real users might ask them.
Text:
{text}
Questions (one per line):"""
)
questions_chain = questions_prompt | llm
response = questions_chain.invoke({"text": text_chunk})
# Split response into individual questions
questions = [q.strip() for q in response.content.split('\n') if q.strip()]
return questions
# Test question generation
test_questions = generate_potential_questions(test_chunk)
print("Generated questions for the chunk:")
print("-" * 50)
for i, question in enumerate(test_questions, 1):
print(f"{i}. {question}")
python
Generated questions for the chunk:
--------------------------------------------------
1. 1. What are the mathematical foundations of neural networks?
2. 2. What are some of the advanced architectures and models of neural networks?
3. 3. What are the applications of neural networks across industries?
4. 4. What tools and frameworks are used in implementing neural networks?
5. 5. What are the challenges and limitations of neural networks?
This function analyzes the content and generates natural questions that users might ask. When someone searches “What are Neural Networks?”, they’re more likely to match a chunk that explicitly contains this question.
7. Adding Topic Tags and Metadata
Let’s add our third augmentation: topic tags and difficulty levels. This helps categorize and filter content.
python
def generate_metadata_tags(text_chunk):
"""
Generate topic tags and metadata for a document chunk
"""
metadata_prompt = PromptTemplate(
input_variables=["text"],
template="""Analyze the following text and provide:
1. 3-5 topic tags (key concepts/subjects)
2. Difficulty level (Beginner/Intermediate/Advanced)
3. Content type (Definition/Explanation/Example/Tutorial/etc.)
Format your response as JSON:
{{"topics": ["tag1", "tag2", "tag3"], "difficulty": "level", "content_type": "type"}}
Text:
{text}
Metadata:"""
)
metadata_chain = metadata_prompt | llm
response = metadata_chain.invoke({"text": text_chunk})
try:
# Parse JSON response
metadata = json.loads(response.content.strip())
return metadata
except json.JSONDecodeError:
# Fallback if JSON parsing fails
return {
"topics": ["general"],
"difficulty": "Intermediate",
"content_type": "Information"
}
# Test metadata generation
test_metadata = generate_metadata_tags(test_chunk)
print("Generated metadata:")
print("-" * 50)
print(f"Topics: {test_metadata['topics']}")
print(f"Difficulty: {test_metadata['difficulty']}")
print(f"Content Type: {test_metadata['content_type']}")
python
Generated metadata:
--------------------------------------------------
Topics: ['Neural Networks', 'Deep Learning', 'Artificial Intelligence', 'Machine Learning', 'Convolutional Neural Networks']
Difficulty: Advanced
Content Type: Guide
This function extracts key topics, estimates difficulty level, and categorizes the content type. This metadata helps with filtering and provides additional text for matching.
8. Creating Enhanced Document Chunks
Now let’s combine all our augmentations into enhanced document chunks
python
def create_augmented_chunk(original_chunk, chunk_index):
"""
Create an augmented version of a document chunk with all enhancements
"""
print(f"Augmenting chunk {chunk_index + 1}...")
original_text = original_chunk.page_content
# Generate all augmentations
summary = generate_document_summary(original_text)
questions = generate_potential_questions(original_text)
metadata = generate_metadata_tags(original_text)
# Combine everything into enhanced content
questions_text = "\n".join([f"Q: {q}" for q in questions])
topics_text = ", ".join(metadata['topics'])
augmented_content = f"""ORIGINAL CONTENT:
{original_text}
SUMMARY:
{summary}
POTENTIAL QUESTIONS:
{questions_text}
TOPICS: {topics_text}
DIFFICULTY: {metadata['difficulty']}
CONTENT TYPE: {metadata['content_type']}"""
# Create enhanced document with metadata
enhanced_chunk = Document(
page_content=augmented_content,
metadata={
**original_chunk.metadata,
'chunk_index': chunk_index,
'original_length': len(original_text),
'augmented_length': len(augmented_content),
'topics': metadata['topics'],
'difficulty': metadata['difficulty'],
'content_type': metadata['content_type'],
'has_augmentation': True
}
)
return enhanced_chunk
# Process a chunk to test (we'll do all later)
print("Testing augmentation on a chunk...")
test_augmented_chunks = []
augmented_chunk = create_augmented_chunk(document_chunks[5], 5)
test_augmented_chunks.append(augmented_chunk)
time.sleep(1) # Be nice to the API
print(f"\nCreated {len(test_augmented_chunks)} augmented chunks")
# Show example of augmented content
if test_augmented_chunks:
example_chunk = test_augmented_chunks[0]
print("\nExample augmented chunk:")
print("=" * 60)
print(example_chunk.page_content[:500] + "...")
print(f"\nMetadata: {example_chunk.metadata}")
python
Testing augmentation on a chunk...
Augmenting chunk 6...
Created 1 augmented chunks
Example augmented chunk:
============================================================
ORIGINAL CONTENT:
learning algorithms that adjust connection weights based on training data. While significantly
simplified compared to biological neural networks, these artificial systems capture essential aspects
of neural computation and have proven remarkably effective across diverse applications.
The versatility of neural networks stems from their ability to learn hierarchical representations of
data, automatically discovering features and patterns at multiple levels of abstraction. Lower l...
Metadata: {'producer': 'Skia/PDF m136', 'creator': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36', 'creationdate': '2025-05-29T08:55:52+00:00', 'title': 'Comprehensive Guide to Neural Networks', 'moddate': '2025-05-29T08:55:52+00:00', 'source': 'Neural Networks.pdf', 'total_pages': 51, 'page': 1, 'page_label': '2', 'chunk_index': 5, 'original_length': 780, 'augmented_length': 1895, 'topics': ['learning algorithms', 'artificial neural networks', 'hierarchical representations', 'deep neural networks'], 'difficulty': 'Advanced', 'content_type': 'Explanation', 'has_augmentation': True}
This function takes an original chunk and creates a super-enhanced version with summary, questions, and metadata.
The augmented content is much richer and provides many more ways for users to find relevant information.
9. Processing All Documents with Rate Limiting
Now let’s process all our document chunks with proper rate limiting to avoid API limits
python
def augment_all_documents(document_chunks, delay_seconds=2):
"""
Augment all document chunks with rate limiting
"""
print(f"Starting augmentation of {len(document_chunks)} chunks...")
print(f"Using {delay_seconds}s delay between requests")
augmented_chunks = []
errors = []
for i, chunk in enumerate(document_chunks):
try:
augmented_chunk = create_augmented_chunk(chunk, i)
augmented_chunks.append(augmented_chunk)
# Progress update every 10 chunks
if (i + 1) % 10 == 0:
print(f" Completed {i + 1} chunks")
# Rate limiting
if i < len(document_chunks) - 1: # Don't delay after last chunk
time.sleep(delay_seconds)
except Exception as e:
print(f" Error processing chunk {i + 1}: {e}")
errors.append((i, str(e)))
# Add original chunk as fallback
fallback_chunk = Document(
page_content=chunk.page_content,
metadata={
**chunk.metadata,
'chunk_index': i,
'has_augmentation': False,
'error': str(e)
}
)
augmented_chunks.append(fallback_chunk)
print(f"\n Augmentation complete!")
print(f"Successfully augmented: {len(augmented_chunks) - len(errors)} chunks")
print(f"Errors encountered: {len(errors)} chunks")
return augmented_chunks, errors
# Process all documents (this will take a while with rate limiting)
print("Starting full document augmentation...")
all_augmented_chunks, processing_errors = augment_all_documents(
document_chunks[:20], # Process first 20 chunks for demo
delay_seconds=1
)
print(f"\nFinal results:")
print(f"Total chunks processed: {len(all_augmented_chunks)}")
print(f"Successfully augmented: {len([c for c in all_augmented_chunks if c.metadata.get('has_augmentation', False)])}")
print(f"Fallback chunks: {len([c for c in all_augmented_chunks if not c.metadata.get('has_augmentation', False)])}")
python
Starting full document augmentation...
Starting augmentation of 20 chunks...
Using 1s delay between requests
Augmenting chunk 1...
Augmenting chunk 2...
Augmenting chunk 3...
Augmenting chunk 4...
Augmenting chunk 5...
Augmenting chunk 6...
Augmenting chunk 7...
Augmenting chunk 8...
Augmenting chunk 9...
Augmenting chunk 10...
Completed 10 chunks
Augmenting chunk 11...
Augmenting chunk 12...
Augmenting chunk 13...
Augmenting chunk 14...
Augmenting chunk 15...
Augmenting chunk 16...
Augmenting chunk 17...
Augmenting chunk 18...
Augmenting chunk 19...
Augmenting chunk 20...
Completed 20 chunks
Augmentation complete!
Successfully augmented: 20 chunks
Errors encountered: 0 chunks
Final results:
Total chunks processed: 20
Successfully augmented: 20
Fallback chunks: 0
This function processes all your documents with proper error handling and rate limiting. It’s important to be respectful of API limits when doing bulk processing.
10. Creating the Enhanced Vector Store
Now let’s create our vector store using the augmented documents
python
# Initialize embeddings model
embeddings_model = OpenAIEmbeddings()
# Create vector store with augmented documents
print("Creating enhanced vector store...")
augmented_vector_store = FAISS.from_documents(
documents=all_augmented_chunks,
embedding=embeddings_model
)
print(f"Enhanced vector store created with {len(all_augmented_chunks)} augmented documents")
python
Creating enhanced vector store...
Enhanced vector store created with 20 augmented documents
The vector store now contains rich, augmented content instead of just the original text. This dramatically improves search capabilities.
11. Building the Enhanced Retrieval System
Let’s create a retrieval system that shows you how the augmentation helps
python
def enhanced_retrieve_documents(query, vector_store, k=3):
"""
Retrieve documents using augmented content and show enhancement details
"""
# Get search results
retrieved_docs = vector_store.similarity_search(query, k=k)
# Analyze results
enhanced_results = []
original_results = []
for doc in retrieved_docs:
if doc.metadata.get('has_augmentation', False):
enhanced_results.append(doc)
else:
original_results.append(doc)
return {
'all_results': retrieved_docs,
'enhanced_results': enhanced_results,
'original_results': original_results,
'enhancement_ratio': len(enhanced_results) / len(retrieved_docs) if retrieved_docs else 0
}
# Test enhanced retrieval
test_query = "What is a neural network and how does it work?"
retrieval_results = enhanced_retrieve_documents(test_query, augmented_vector_store, k=5)
print(f"Query: '{test_query}'")
print("=" * 60)
print(f"Total results: {len(retrieval_results['all_results'])}")
print(f"Enhanced results: {len(retrieval_results['enhanced_results'])}")
print(f"Original results: {len(retrieval_results['original_results'])}")
print(f"Enhancement ratio: {retrieval_results['enhancement_ratio']:.1%}")
# Show how augmentation helped
if retrieval_results['enhanced_results']:
print(f"\n ENHANCED RESULTS (showing augmentation benefits):")
for i, doc in enumerate(retrieval_results['enhanced_results'][:2]):
print(f"\nResult {i+1}:")
print(f"Topics: {doc.metadata.get('topics', 'N/A')}")
print(f"Difficulty: {doc.metadata.get('difficulty', 'N/A')}")
print(f"Content: {doc.page_content[:200]}...")
python
Query: 'What is a neural network and how does it work?'
============================================================
Total results: 5
Enhanced results: 5
Original results: 0
Enhancement ratio: 100.0%
ENHANCED RESULTS (showing augmentation benefits):
Result 1:
Topics: ['Neural Networks', 'Artificial Intelligence', 'Machine Learning', 'Pattern Recognition', 'Problem Solving']
Difficulty: Beginner
Content: ORIGINAL CONTENT:
Chapter 1: Introduction to Neural Networks
Neural networks represent one of the most significant breakthroughs in artificial intelligence and
machine learning, offering a computation...
Result 2:
Topics: ['Neural Networks', 'Machine Learning', 'Data Analysis', 'Programming', 'Mathematical Models']
Difficulty: Intermediate
Content: ORIGINAL CONTENT:
called neurons or units, that work together to process information and learn from data. Unlike
traditional programming approaches where explicit instructions are written to solve spe...
This function shows you exactly how the augmentation is helping your searches and what type of enhanced content is being retrieved.
12. Comparing Augmented vs Traditional RAG
Let’s create a side-by-side comparison to see the difference
python
# Create traditional vector store for comparison
print("Creating traditional vector store for comparison...")
traditional_vector_store = FAISS.from_documents(
documents=document_chunks[:20], # Same chunks, no augmentation
embedding=embeddings_model
)
def compare_retrieval_approaches(query):
"""
Compare traditional RAG vs document augmentation RAG
"""
print(f" QUERY: '{query}'")
print("=" * 70)
# Traditional RAG
print("\n TRADITIONAL RAG:")
traditional_results = traditional_vector_store.similarity_search(query, k=2)
for i, doc in enumerate(traditional_results):
print(f" {i+1}. {doc.page_content[:120]}...")
# Document Augmentation RAG
print(f"\n DOCUMENT AUGMENTATION RAG:")
aug_results = enhanced_retrieve_documents(query, augmented_vector_store, k=2)
for i, doc in enumerate(aug_results['all_results']):
is_enhanced = doc.metadata.get('has_augmentation', False)
marker = "" if is_enhanced else ""
# Show original content part for fair comparison
content = doc.page_content
if is_enhanced and "ORIGINAL CONTENT:" in content:
original_part = content.split("SUMMARY:")[0].replace("ORIGINAL CONTENT:", "").strip()
print(f" {i+1}. {marker} {original_part[:120]}...")
else:
print(f" {i+1}. {marker} {content[:120]}...")
# Show augmentation benefits
if aug_results['enhanced_results']:
example_doc = aug_results['enhanced_results'][0]
topics = example_doc.metadata.get('topics', [])
difficulty = example_doc.metadata.get('difficulty', 'Unknown')
print(f"\n AUGMENTATION INSIGHTS:")
print(f" Topics found: {', '.join(topics)}")
print(f" Difficulty level: {difficulty}")
print(f" Enhanced chunks: {len(aug_results['enhanced_results'])}/{len(aug_results['all_results'])}")
# Test different types of queries
comparison_queries = [
"Why do deep networks generalize well even with more parameters than data?",
"What is the vanishing gradient problem?",
"What is information bottleneck theory used for?"
]
for query in comparison_queries:
compare_retrieval_approaches(query)
print("\n" + "-"*70 + "\n")
python
Creating traditional vector store for comparison...
QUERY: 'Why do deep networks generalize well even with more parameters than data?'
======================================================================
TRADITIONAL RAG:
1. learning algorithms that adjust connection weights based on training data. While significantly
simplified compared to bi...
2. function, given sufficient hidden units. This universal approximation property suggested that multi-
layer networks coul...
DOCUMENT AUGMENTATION RAG:
1. learning algorithms that adjust connection weights based on training data. While significantly
simplified compared to bi...
2. makes neural networks particularly valuable for tackling problems involving high-dimensional data,
non-linear relationsh...
AUGMENTATION INSIGHTS:
Topics found: learning algorithms, artificial neural networks, hierarchical representations, deep neural networks
Difficulty level: Intermediate
Enhanced chunks: 2/2
----------------------------------------------------------------------
QUERY: 'What is the vanishing gradient problem?'
======================================================================
TRADITIONAL RAG:
1. function, given sufficient hidden units. This universal approximation property suggested that multi-
layer networks coul...
2. perceptrons could not solve non-linearly separable problems, such as the XOR function, which
required the ability to lea...
DOCUMENT AUGMENTATION RAG:
1. perceptrons could not solve non-linearly separable problems, such as the XOR function, which
required the ability to lea...
2. algorithm would always find a solution for linearly separable problems, providing theoretical
guarantees for the learnin...
AUGMENTATION INSIGHTS:
Topics found: Perceptrons, Non-linearly separable problems, XOR function, AI winter, Neural networks
Difficulty level: Advanced
Enhanced chunks: 2/2
----------------------------------------------------------------------
QUERY: 'What is information bottleneck theory used for?'
======================================================================
TRADITIONAL RAG:
1. reach of artificial intelligence.
The recent surge in neural network capabilities and applications has been driven by se...
2. perceptrons could not solve non-linearly separable problems, such as the XOR function, which
required the ability to lea...
DOCUMENT AUGMENTATION RAG:
1. reach of artificial intelligence.
The recent surge in neural network capabilities and applications has been driven by se...
2. makes neural networks particularly valuable for tackling problems involving high-dimensional data,
non-linear relationsh...
AUGMENTATION INSIGHTS:
Topics found: Artificial Intelligence, Neural Networks, Machine Learning, Data Training, Network Architectures
Difficulty level: Advanced
Enhanced chunks: 2/2
----------------------------------------------------------------------
This comparison shows how document augmentation provides richer, more discoverable content compared to traditional RAG approaches.
13. Creating a Complete QA System
Now let’s build a complete question-answering system that leverages our augmented documents
python
def answer_with_augmented_rag(question, vector_store, provide_insights=True):
"""
Answer questions using document augmentation RAG
"""
print(f"Question: {question}")
print("\n Searching augmented knowledge base...")
# Retrieve relevant augmented documents
retrieval_results = enhanced_retrieve_documents(question, vector_store, k=5)
# Extract original content for answer generation
context_parts = []
metadata_insights = []
for doc in retrieval_results['all_results']:
# Extract original content from augmented chunks
content = doc.page_content
if doc.metadata.get('has_augmentation', False):
if "ORIGINAL CONTENT:" in content:
original_content = content.split("SUMMARY:")[0].replace("ORIGINAL CONTENT:", "").strip()
context_parts.append(original_content)
# Collect metadata insights
topics = doc.metadata.get('topics', [])
difficulty = doc.metadata.get('difficulty', 'Unknown')
content_type = doc.metadata.get('content_type', 'Unknown')
metadata_insights.append({
'topics': topics,
'difficulty': difficulty,
'content_type': content_type
})
else:
context_parts.append(content)
else:
context_parts.append(content)
context = "\n\n".join(context_parts)
# Generate answer
answer_prompt = PromptTemplate(
input_variables=["question", "context"],
template="""Based on the following context from augmented documents, provide a comprehensive answer to the question.
Context:
{context}
Question: {question}
Answer:"""
)
answer_chain = answer_prompt | llm
final_answer = answer_chain.invoke({
"question": question,
"context": context
})
print("\nAnswer:")
print("=" * 60)
print(textwrap.fill(final_answer.content, width=80))
if provide_insights and metadata_insights:
print(f"\n KNOWLEDGE INSIGHTS:")
print("-" * 40)
# Aggregate topics
all_topics = []
difficulties = []
content_types = []
for insight in metadata_insights:
all_topics.extend(insight['topics'])
difficulties.append(insight['difficulty'])
content_types.append(insight['content_type'])
# Show unique topics
unique_topics = list(set(all_topics))
print(f"Related topics: {', '.join(unique_topics[:5])}")
# Show difficulty distribution
difficulty_counts = {d: difficulties.count(d) for d in set(difficulties)}
print(f"Content difficulty: {difficulty_counts}")
# Show enhancement stats
enhanced_count = len(retrieval_results['enhanced_results'])
total_count = len(retrieval_results['all_results'])
print(f"Enhanced results: {enhanced_count}/{total_count} ({enhanced_count/total_count:.1%})")
# Test the complete system
test_questions = [
"How does the universal approximation theorem apply to neural networks?",
"How did the backpropagation algorithm revive interest in neural networks?",
"Why do deep networks generalize well even with more parameters than data?"
]
for question in test_questions:
answer_with_augmented_rag(question, augmented_vector_store)
print("\n" + "="*80 + "\n")
python
Question: How does the universal approximation theorem apply to neural networks?
Searching augmented knowledge base...
Answer:
============================================================
The universal approximation theorem applies to neural networks by suggesting
that multi-layer networks could, in principle, solve complex problems that were
impossible for single-layer perceptrons, given sufficient hidden units. This
means that neural networks have the ability to approximate complex functions and
model intricate relationships that would be difficult or impossible to capture
using conventional mathematical or algorithmic approaches. This capability makes
neural networks particularly valuable for tackling problems involving high-
dimensional data, non-linear relationships, and complex patterns that
traditional methods struggle to handle effectively.
KNOWLEDGE INSIGHTS:
----------------------------------------
Related topics: Programming, hierarchical representations, Mathematical Models, Machine Learning, deep neural networks
Content difficulty: {'Intermediate': 3, 'Advanced': 1, 'Beginner': 1}
Enhanced results: 5/5 (100.0%)
================================================================================
Question: How did the backpropagation algorithm revive interest in neural networks?
Searching augmented knowledge base...
Answer:
============================================================
The backpropagation algorithm revived interest in neural networks by providing
an effective learning algorithm for multi-layer networks. Prior to its
development, it was unclear how to adjust the weights of hidden units in multi-
layer networks that were not directly connected to the output. The
backpropagation algorithm, discovered by several researchers including David
Rumelhart, Geoffrey Hinton, and Ronald Williams, solved this problem by
providing a method to adjust connection weights based on training data. This
breakthrough allowed multi-layer networks to overcome the limitations of single-
layer perceptrons and solve complex problems that were previously impossible,
leading to a resurgence in the interest and development of neural networks.
KNOWLEDGE INSIGHTS:
----------------------------------------
Related topics: hierarchical representations, Expert Systems, Machine Learning, Data Training, Neural Networks
Content difficulty: {'Intermediate': 1, 'Advanced': 3, 'Beginner': 1}
Enhanced results: 5/5 (100.0%)
================================================================================
Question: Why do deep networks generalize well even with more parameters than data?
Searching augmented knowledge base...
Answer:
============================================================
Deep networks generalize well even with more parameters than data due to their
ability to learn hierarchical representations of data. They can automatically
discover features and patterns at multiple levels of abstraction. Lower layers
in a neural network might detect simple features like edges or basic patterns,
while higher layers combine these simple features to recognize complex objects,
concepts, or relationships. This hierarchical learning capability enables neural
networks to generalize beyond their training data and make predictions or
decisions about new, previously unseen inputs. Furthermore, the development of
the backpropagation algorithm allows for the adjustment of weights based on
output errors, even in multi-layer networks. This, along with the availability
of large datasets for training, increased computational power, improved
algorithms and training techniques, and a better understanding of network
architectures and design principles, has enabled deep networks to perform
remarkably well on complex real-world problems.
KNOWLEDGE INSIGHTS:
----------------------------------------
Related topics: artificial neural networks, Deep Neural Networks, deep neural networks, Non-linear Relationships, Backpropagation Algorithm
Content difficulty: {'Intermediate': 3, 'Advanced': 2}
Enhanced results: 5/5 (100.0%)
================================================================================
This complete system leverages all the augmentation benefits while providing insights into what type of enhanced content contributed to the answer.
The key advantage is that Document Augmentation RAG doesn’t just make content searchable – it makes it discoverable. Users can find information using their own vocabulary, questions, and mental models, rather than having to guess the exact terms used by document authors.
Free Course
Master Core Python — Your First Step into AI/ML
Build a strong Python foundation with hands-on exercises designed for aspiring Data Scientists and AI/ML Engineers.
Start Free Course →Trusted by 50,000+ learners
Related Course
Master Gen AI — Hands-On
Join 5,000+ students at edu.machinelearningplus.com
Explore Course

