machine learning +
LLM Temperature, Top-P, and Top-K Explained — With Python Simulations
Corrective RAG: Fixing LLM Errors for Accurate AI Response
Corrective RAG (CRAG) is an advanced RAG technique that adds a quality check layer to your retrieval system. Instead of blindly trusting retrieved documents, CRAG evaluates their relevance and takes corrective action when the retrieved information is poor, irrelevant, or insufficient.
Corrective RAG (CRAG) is an advanced RAG technique that adds a quality check layer to your retrieval system. Instead of blindly trusting retrieved documents, CRAG evaluates their relevance and takes corrective action when the retrieved information is poor, irrelevant, or insufficient.
I’ll bet you’ve experienced this: you ask a RAG system a perfectly reasonable question, but it gives you a disappointing answer. You rephrase the question, try again, and still get subpar results.
The problem isn’t your question – it’s that the retrieved documents weren’t good enough in the first place.
This is where CRAG comes in.
Think of it as adding a quality inspector to your RAG pipeline. Instead of just grabbing documents and hoping they’re relevant, CRAG actually checks if the retrieved information is good enough. If not, it takes corrective action.
Let’s build a CRAG system that can intelligently work with robotics documents, step by step.
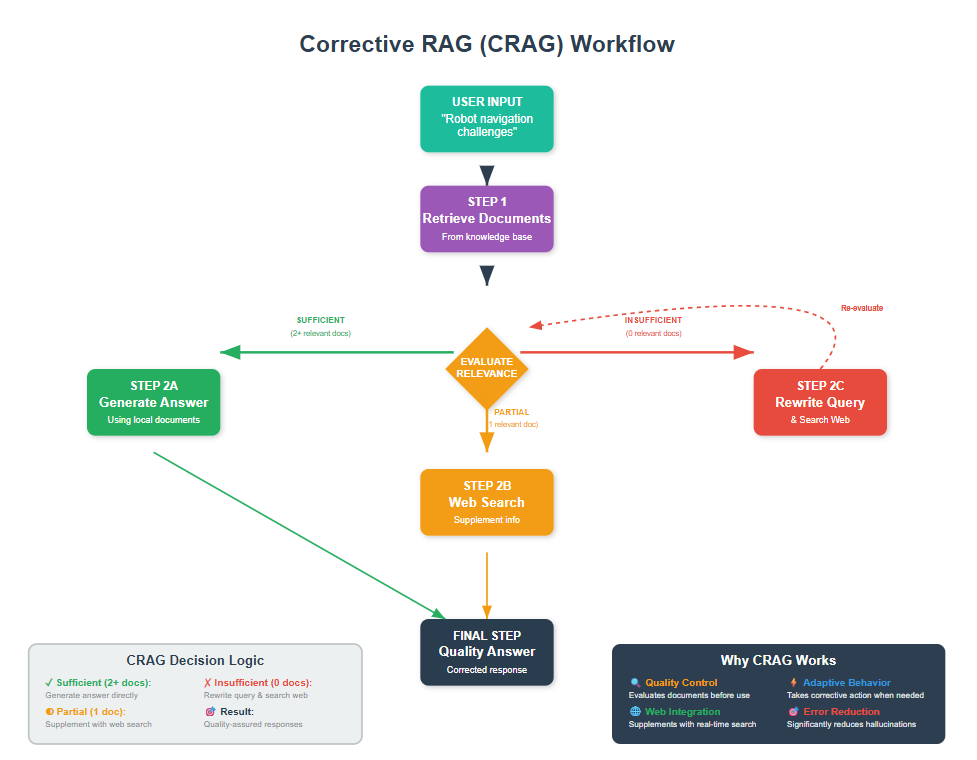
1. Understanding the Problem CRAG Solves
Before we jump into code, let me paint you a picture of what typically goes wrong with basic RAG.
You have a source on robotics and you ask: “What are the main challenges in autonomous navigation?”
Traditional RAG might retrieve documents about general robotics or sensor specifications. The system doesn’t know these documents are only partially relevant – it just uses whatever similarity search returns.
CRAG fixes this by adding three crucial steps:
- Evaluate: Is the retrieved information actually relevant?
- Decide: Should we use it as-is, refine it, or look elsewhere?
- Correct: Take action based on that decision
This makes your RAG system much more robust and reliable.
2. Setting Up Your Environment
Let’s get everything ready. I’ll assume you have Python and VS Code set up with Jupyter notebooks.
First, install the packages we need:
bash
conda create -p rag python==3.12
conda activate rag
pip install ipykernel
pip install langchain langchain-openai python-dotenv faiss-cpu pypdf requests beautifulsoup4 tavily-python
Now let’s import everything and set up our API keys:
python
import os
import json
import requests
from typing import List, Tuple
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.vectorstores import FAISS
from langchain.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
# Load environment variables
load_dotenv()
# Set your API keys
os.environ["OPENAI_API_KEY"] = os.getenv('OPENAI_API_KEY')
os.environ["TAVILY_API_KEY"] = os.getenv('TAVILY_API_KEY')
print("Environment setup complete!")
python
Environment setup complete!
Create a .env file in your project directory
python
OPENAI_API_KEY=your_actual_openai_key_here
TAVILY_API_KEY=your_tavily_key_here
Tavily is specifically designed for AI applications and makes web search incredibly simple compared to scraping websites.
3. Loading Your Robotics Document
Let’s load and process your robotics PDF. This creates our knowledge base that CRAG will intelligently work with.
You can download the pdf here
python
# Load your robotics PDF - replace with your actual file path
pdf_path = "Robotics.pdf"
try:
loader = PyPDFLoader(pdf_path)
raw_documents = loader.load()
print(f" Loaded {len(raw_documents)} pages from robotics PDF")
print(f"Sample content: {raw_documents[0].page_content[:200]}...")
except Exception as e:
print(f" Error loading PDF: {e}")
print("Please make sure your PDF path is correct")
python
Loaded 57 pages from robotics PDF
Sample content: Comprehensive Guide to Robotics
Table of Contents
1. Introduction to Robotics
2. Historical Development of Robotics
3. Fundamental Concepts and Definitions
4. Types and Classifications of Robots
5. Ro...
4. Chunking for Optimal Retrieval
Now we’ll split the document into chunks. This is crucial because CRAG needs to evaluate individual pieces of information.
python
# Configure text splitter for technical content
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # Good size for technical content
chunk_overlap=50, # Preserve context between chunks
separators=["\n\n", "\n", ". ", " "] # Split smartly on paragraphs first
)
# Split documents into chunks
document_chunks = text_splitter.split_documents(raw_documents)
print(f" Split into {len(document_chunks)} chunks")
print(f"Average chunk size: {sum(len(chunk.page_content) for chunk in document_chunks) // len(document_chunks)} characters")
# Show a sample chunk
if document_chunks:
print(f"\nSample chunk:")
print("-" * 50)
print(document_chunks[0].page_content[:300] + "...")
python
Split into 363 chunks
Average chunk size: 423 characters
Sample chunk:
--------------------------------------------------
Comprehensive Guide to Robotics
Table of Contents
1. Introduction to Robotics
2. Historical Development of Robotics
3. Fundamental Concepts and Definitions
4. Types and Classifications of Robots
5. Robot Components and Systems
6. Sensors and Perception
7. Actuators and Motion Systems
8. Control Syst...
For robotics content, 500-character chunks work well because they’re large enough to contain complete technical concepts but small enough for precise retrieval.
5. Creating Your Vector Knowledge Base
Now we’ll create the FAISS vector store that serves as our primary knowledge base.
python
# Initialize embeddings model
embeddings = OpenAIEmbeddings()
# Create FAISS index from document chunks
print(" Creating FAISS vector index...")
faiss_index = FAISS.from_documents(
documents=document_chunks,
embedding=embeddings
)
print(f" Created vector store with {len(document_chunks)} chunks")
# Test basic retrieval
test_query = "Robot navigation challenges"
test_docs = faiss_index.similarity_search(test_query, k=3)
print(f"Test retrieval found {len(test_docs)} documents")
python
Creating FAISS vector index...
Created vector store with 363 chunks
Test retrieval found 3 documents
FAISS is perfect for this because it’s fast, works locally, and gives us the flexibility to tune our retrieval as needed.
6. Building the Document Retrieval Function
Let’s create our document retrieval function. This is the first step in the CRAG process.
python
def retrieve_documents(query, faiss_index, k = 4):
"""
Retrieve top-k most similar documents for a given query
Args:
query: The search query
faiss_index: FAISS vector store
k: Number of documents to retrieve
Returns:
List of retrieved documents
"""
print(f" Retrieving documents for query: '{query}'")
retrieved_docs = faiss_index.similarity_search(query, k=k)
print(f" Found {len(retrieved_docs)} candidate documents")
for i, doc in enumerate(retrieved_docs):
print(f" Doc {i+1}: {doc.page_content[:80]}...")
return retrieved_docs
# Test the retrieval function
sample_query = "Autonomous robot navigation challenges"
retrieved_docs = retrieve_documents(sample_query, faiss_index)
python
Retrieving documents for query: 'Autonomous robot navigation challenges'
Found 4 candidate documents
Doc 1: power transmission, and distributed control systems that can coordinate large nu...
Doc 2: may require high levels of autonomy due to communication limitations. Examples i...
Doc 3: navigate roads without human drivers. While still in development, these systems ...
Doc 4: Visual SLAM systems using camera data are becoming particularly sophisticated an...
This function does basic similarity search but shows us what documents we’re working with. The key insight is that CRAG doesn’t stop here – it evaluates these results.
7. Creating the Document Evaluator – The Heart of CRAG
This is where CRAG gets intelligent. Instead of trusting similarity scores, we actually evaluate whether documents are relevant.
python
def evaluate_documents(query, documents):
"""
Evaluate how well each document answers the query
Args:
query: The original query
documents: List of retrieved documents
Returns:
List of relevance scores (0.0 to 1.0)
"""
print(f" Evaluating {len(documents)} documents for relevance...")
# Create LLM for evaluation
llm = ChatOpenAI(temperature=0, model="gpt-4o-mini")
# Evaluation prompt
eval_prompt = PromptTemplate(
input_variables=["query", "document"],
template="""Evaluate how well this document answers the query on a scale of 0.0 to 1.0:
Query: {query}
Document: {document}
Consider:
- Does the document directly address the query?
- Is the information specific and relevant?
- Would this document help answer the question?
Score (0.0 = completely irrelevant, 1.0 = perfectly relevant): """
)
eval_chain = eval_prompt | llm | StrOutputParser()
scores = []
for i, doc in enumerate(documents):
try:
response = eval_chain.invoke({
"query": query,
"document": doc.page_content[:800] # Limit for evaluation
})
# Extract numerical score from response
score_text = response.strip()
# Look for decimal number in response
import re
score_match = re.search(r'(\d*\.?\d+)', score_text)
score = float(score_match.group(1)) if score_match else 0.5
score = max(0.0, min(1.0, score)) # Clamp between 0 and 1
scores.append(score)
print(f" Doc {i+1} score: {score:.2f}")
except Exception as e:
print(f" Doc {i+1} evaluation failed: {e}")
scores.append(0.5) # Default neutral score
avg_score = sum(scores) / len(scores) if scores else 0
print(f" Average relevance score: {avg_score:.2f}")
return scores
# Test document evaluation
scores = evaluate_documents(sample_query, retrieved_docs)
python
Evaluating 4 documents for relevance...
Doc 1 score: 0.60
Doc 2 score: 0.40
Doc 3 score: 0.20
Doc 4 score: 0.70
Average relevance score: 0.47
This evaluator is the brain of CRAG. It actually reads each document and decides how relevant it is. Notice how we’re being specific about what makes a document relevant.
8. Implementing Web Search for Supplemental Information
When our knowledge base doesn’t have good enough information, CRAG searches the web. We’ll use Tavily – a search API specifically designed for AI applications.
Tavily is like Google, but built specifically for AI systems. Instead of giving you links to click, it gives you the actual content that answers your question. This makes it perfect for CRAG!
python
def web_search(query, num_results = 3):
"""
Search the web using Tavily when our PDF doesn't have enough information
Tavily is a search API designed specifically for AI - it's like Google but
returns actual content instead of just links!
Args:
query: What you're searching for
num_results: How many results you want
Returns:
List of (title, content) pairs
"""
print(f" Searching the web for: '{query}'")
# Check if Tavily API key is available
if not os.getenv('TAVILY_API_KEY'):
print(" No Tavily API key found - using fallback content")
try:
# Import Tavily search tool
from langchain_community.tools import TavilySearchResults
# Create the search tool
search_tool = TavilySearchResults(
max_results=num_results,
search_depth="advanced" # Gets more detailed content
)
# Perform the search - this is the magic line!
search_results = search_tool.invoke(f"robotics {query}")
# Format results for our CRAG system
formatted_results = []
for result in search_results:
title = result.get('title', 'Web Result')
content = result.get('content', result.get('snippet', ''))
if content: # Only add results with actual content
formatted_results.append((title, content))
print(f" Found {len(formatted_results)} results from the web")
return formatted_results
except Exception as e:
print(f" Web search failed: {e}")
return []
# Test the web search function
print(" Testing Tavily web search:")
web_results = web_search(sample_query)
print(f"\nResults:")
for i, (title, content) in enumerate(web_results, 1):
print(f"{i}. {title}")
print(f" {content[:120]}...")
print()
python
Testing Tavily web search:
Searching the web for: 'Autonomous robot navigation challenges'
Found 3 results from the web
Results:
1. Challenges and Solutions for Autonomous Ground Robot Scene ...
The following challenges for the classical autonomous robot navigation pipeline remain for current robotic systems: Perc...
2. ICRA 2024 BARN Challenge - GMU CS Department
The Benchmark Autonomous Robot Navigation (BARN) Challenge aims at creating a benchmark for state-of-the-art navigation ...
3. 4 Key Challenges and Solutions in Autonomous Robot Deployment
Uneven Terrain: Factory floors may have uneven surfaces or obstacles such as ramps, steps, or thresholds that can pose c...
This web search function gives CRAG access to current information beyond your PDF. When the local documents aren’t good enough, it can find better information online.
9. Creating the Response Generator
Now let’s build the function that generates the final answer using the best available information.
python
def generate_response(query, knowledge, sources = None):
"""
Generate response using the provided knowledge and sources
Args:
query: Original query
knowledge: Compiled knowledge from documents/web
sources: List of (title, link) tuples for citation
Returns:
Generated response with sources
"""
print(" Generating final response...")
llm = ChatOpenAI(temperature=0, model="gpt-4o-mini")
# Format sources for citation
sources_text = ""
if sources:
sources_text = "\n\nSources:\n" + "\n".join([
f"- {title}: {link}" if link else f"- {title}"
for title, link in sources
])
response_prompt = PromptTemplate(
input_variables=["query", "knowledge", "sources"],
template="""You are a robotics expert. Answer the question based on the provided knowledge.
Be specific and technical where appropriate. If the knowledge is limited, acknowledge what you can answer confidently and what might need additional research.
Query: {query}
Knowledge: {knowledge}
{sources}
Answer:"""
)
response_chain = response_prompt | llm | StrOutputParser()
response = response_chain.invoke({
"query": query,
"knowledge": knowledge,
"sources": sources_text
})
return response
# Test response generation
test_knowledge = "Autonomous robot navigation faces several key challenges including dynamic obstacle avoidance, real-time path planning, and accurate localization in GPS-denied environments."
test_response = generate_response(sample_query, test_knowledge)
print("Generated response:")
print(test_response)
python
Generating final response...
Generated response:
Autonomous robot navigation indeed presents a variety of challenges that can significantly impact the effectiveness and reliability of robotic systems. Here are some of the primary challenges in more detail:
1. **Dynamic Obstacle Avoidance**:
- **Challenge**: Robots must be able to detect and respond to moving obstacles in real-time, such as pedestrians, vehicles, or other robots. This requires sophisticated perception systems that can interpret sensor data (e.g., LiDAR, cameras, ultrasonic sensors) to identify and predict the movement of these obstacles.
- **Technical Considerations**: Algorithms such as Rapidly-exploring Random Trees (RRT) or Dynamic Window Approach (DWA) can be employed for real-time path planning. Additionally, machine learning techniques can enhance the robot's ability to predict the behavior of dynamic obstacles.
2. **Real-Time Path Planning**:
- **Challenge**: Generating an optimal path from a start to a goal position while considering the current environment and any obstacles is a complex task. The path must be recalculated frequently as the robot moves and as the environment changes.
- **Technical Considerations**: Techniques like A* search, Dijkstra's algorithm, or more advanced methods like the Hybrid A* algorithm can be used for static environments. For dynamic environments, algorithms that incorporate feedback loops and real-time data, such as Model Predictive Control (MPC), are often necessary.
3. **Accurate Localization in GPS-Denied Environments**:
- **Challenge**: In many indoor or urban environments, GPS signals may be weak or unavailable, making it difficult for robots to determine their precise location. Accurate localization is crucial for effective navigation.
- **Technical Considerations**: Techniques such as Simultaneous Localization and Mapping (SLAM) can be employed, where the robot builds a map of its environment while simultaneously keeping track of its position within that map. Sensor fusion methods that combine data from various sensors (e.g., IMU, odometry, visual data) can also improve localization accuracy.
4. **Sensor Noise and Uncertainty**:
- **Challenge**: Sensors are often subject to noise and inaccuracies, which can lead to errors in perception and navigation. This uncertainty must be managed to ensure reliable operation.
- **Technical Considerations**: Kalman filters and particle filters are commonly used to estimate the state of the robot and its environment while accounting for sensor noise.
5. **Computational Limitations**:
- **Challenge**: Real-time processing of sensor data and path planning algorithms can be computationally intensive, especially for complex environments. Limited processing power can hinder the robot's ability to navigate effectively.
- **Technical Considerations**: Optimizing algorithms for efficiency, using hardware acceleration (e.g., GPUs), and employing techniques like hierarchical planning can help mitigate these limitations.
6. **Environmental Variability**:
- **Challenge**: Robots must be able to navigate in a variety of environments, which may have different terrains, lighting conditions, and obstacles. This variability can complicate navigation strategies.
- **Technical Considerations**: Developing adaptable algorithms that can learn from experience and adjust to new environments (e.g., through reinforcement learning) can enhance a robot's ability to navigate in diverse conditions.
7. **Human-Robot Interaction**:
- **Challenge**: In environments shared with humans, robots must navigate safely and effectively while considering human behavior and intentions.
- **Technical Considerations**: Implementing social navigation strategies that allow robots to predict and respond to human movements can improve safety and efficiency.
In summary, while there are established methods and technologies to address these challenges, ongoing research and development are essential to enhance the robustness and adaptability of autonomous navigation systems. Each challenge may require tailored solutions depending on the specific application and operational environment.
This generator is smart about using the information it’s given and being honest about limitations. Notice how it includes source citations when available.
10. Building the Complete CRAG Process
Now let’s put it all together into the main CRAG function that orchestrates the entire process.
python
def crag_process(query, faiss_index, relevance_threshold = 0.6):
"""
Complete CRAG process: retrieve, evaluate, correct, and generate
Args:
query: User query
faiss_index: Vector store for document retrieval
relevance_threshold: Minimum average score to use retrieved docs
Returns:
Final generated response
"""
print(f"\n Starting CRAG process for: '{query}'")
print("=" * 60)
# Step 1: Retrieve documents
retrieved_docs = retrieve_documents(query, faiss_index)
# Step 2: Evaluate document relevance
eval_scores = evaluate_documents(query, retrieved_docs)
avg_score = sum(eval_scores) / len(eval_scores) if eval_scores else 0
# Step 3: Decide corrective action based on scores
print(f"\n Decision Making:")
print(f" Average relevance score: {avg_score:.2f}")
print(f" Threshold: {relevance_threshold}")
knowledge = ""
sources = []
if avg_score >= relevance_threshold:
# Use retrieved documents - they're good enough
print(" Using retrieved documents (sufficient quality)")
knowledge = "\n\n".join([doc.page_content for doc in retrieved_docs])
sources = [("Local Knowledge Base", "") for _ in retrieved_docs]
else:
# Documents aren't good enough - supplement with web search
print(" Supplementing with web search (insufficient quality)")
# Use best local docs if any are decent
decent_docs = [
doc for doc, score in zip(retrieved_docs, eval_scores)
if score >= 0.4
]
if decent_docs:
local_knowledge = "\n\n".join([doc.page_content for doc in decent_docs])
knowledge += local_knowledge
sources.extend([("Local Knowledge Base", "") for _ in decent_docs])
# Add web search results
web_results = web_search(query)
if web_results:
web_knowledge = "\n\n".join([content for title, content in web_results])
knowledge += f"\n\nWeb Information:\n{web_knowledge}"
sources.extend([(title, "") for title, content in web_results])
# Step 4: Generate final response
response = generate_response(query, knowledge, sources)
print(f"\n CRAG process complete!")
return response
# Test the complete CRAG process
test_query = "What are the main challenges in autonomous robot navigation?"
final_response = crag_process(test_query, faiss_index, relevance_threshold=0.6)
print("\n" + "="*60)
print("FINAL ANSWER:")
print("="*60)
print(final_response)
python
Starting CRAG process for: 'What are the main challenges in autonomous robot navigation?'
============================================================
Retrieving documents for query: 'What are the main challenges in autonomous robot navigation?'
Found 4 candidate documents
Doc 1: power transmission, and distributed control systems that can coordinate large nu...
Doc 2: may require high levels of autonomy due to communication limitations. Examples i...
Doc 3: and control that have proven difficult to achieve. Fine manipulation tasks, hand...
Doc 4: demand predictable response times. Balancing computational requirements with pow...
Evaluating 4 documents for relevance...
Doc 1 score: 0.60
Doc 2 score: 0.20
Doc 3 score: 0.60
Doc 4 score: 0.40
Average relevance score: 0.45
Decision Making:
Average relevance score: 0.45
Threshold: 0.6
Supplementing with web search (insufficient quality)
Searching the web for: 'What are the main challenges in autonomous robot navigation?'
Found 3 results from the web
Generating final response...
CRAG process complete!
============================================================
FINAL ANSWER:
============================================================
Autonomous robot navigation presents several significant challenges that stem from the complexity of operating in dynamic and unstructured environments. Here are the main challenges:
1. **Simultaneous Localization and Mapping (SLAM)**: While SLAM technologies have advanced, they still face challenges in real-time performance, particularly in dynamic environments where the robot must continuously update its map while localizing itself. Factors such as sensor noise, rapid changes in the environment, and the need for high accuracy can complicate SLAM implementations.
2. **Object Detection and Scene Understanding**: Reliable object detection is crucial for navigation. Robots must identify and locate various objects, both static and dynamic, in their environment. Challenges include:
- **Occlusion**: Objects may be partially hidden from view, making detection difficult.
- **Lighting Conditions**: Variability in lighting can affect sensor performance, leading to inaccuracies.
- **Sensor Limitations**: Different sensors (e.g., LiDAR, cameras) have varying levels of accuracy and can be affected by environmental factors like reflections and shadows.
3. **Path Planning**: Autonomous robots must navigate through complex terrains, which can include uneven surfaces, obstacles, and previously unseen environments. Path planning algorithms must be robust enough to handle these variations and adapt in real-time to changes in the environment. This includes distinguishing between global path planning (long-term navigation) and local path planning (short-term obstacle avoidance).
4. **Real-Time Processing and Decision-Making**: The need for real-time processing creates significant computational challenges. Robots must make quick decisions based on sensor data, which requires efficient algorithms that can operate within the constraints of available computational resources. Balancing computational load with power consumption and size is a persistent challenge.
5. **Integration Complexity**: Modern autonomous robots are composed of numerous interdependent components, including sensors, actuators, and control systems. The integration of these components can lead to increased complexity in design, debugging, and maintenance. Ensuring that all parts work together seamlessly is a significant engineering challenge.
6. **Adaptation to Unpredictable Conditions**: Robots must be able to adapt to unexpected conditions, such as sudden obstacles or changes in terrain. This requires advanced AI algorithms capable of learning from experience and adjusting their behavior accordingly.
7. **Safety and Human Interaction**: Ensuring safe operation in environments shared with humans is critical. Robots must be able to recognize and respond to human presence and behavior, which adds another layer of complexity to navigation and control systems.
8. **Infrastructure and Environmental Factors**: In many cases, the physical environment may not be designed for robot navigation. This includes issues like narrow pathways, stairs, or doors that require manipulation. Robots must be equipped to handle these interactions, which can be challenging.
In summary, while significant progress has been made in autonomous robot navigation, challenges remain in areas such as SLAM, object detection, path planning, real-time processing, system integration, adaptability, safety, and environmental interaction. Addressing these challenges requires ongoing research and development in robotics, AI, and sensor technologies.
This is the heart of CRAG – the intelligent decision-making process. Notice how it:
- Evaluates document quality
- Makes decisions based on scores
- Takes corrective action when needed
- Combines the best available information
The key insight is that not all retrieved documents are worth using. By adding this quality control layer, CRAG dramatically improves the reliability and accuracy of your robotics Q&A system.
That’s the power of Corrective RAG: making AI systems that don’t just find information, but actually think about whether that information is worth using.
Free Course
Master Core Python — Your First Step into AI/ML
Build a strong Python foundation with hands-on exercises designed for aspiring Data Scientists and AI/ML Engineers.
Start Free Course →Trusted by 50,000+ learners
Related Course
Master Gen AI — Hands-On
Join 5,000+ students at edu.machinelearningplus.com
Explore Course

