machine learning +
LLM Temperature, Top-P, and Top-K Explained — With Python Simulations
Hypothetical Document Embedding (HyDE) – A Smarter RAG method to Search Documents
Learn how HyDE (Hypothetical Document Embeddings) improves RAG systems by creating richer query embeddings for smarter, more accurate AI-driven retrievals.
Hypothetical Document Embeddings (HyDE) is an advanced technique in information retrieval (IR) for RAG systems designed to improve search accuracy when little or relevant documents exist in the dataset yet. It leverages large language models (LLMs) to generate “hypothetical” documents that might answer a query, then uses their embeddings for similarity search.
Have you ever asked something to a RAG based chatbot and felt like the response just didn’t get a satisfactory answer? Then, you had to re-ask the question in a different form, and this goes on for few iterations?
This can happen when the retrieved context information given to the LLM was not sufficient.
HyDE provides a unique way to address this.
Instead of searching the vector store for the user query, HyDE first generates an answer from the LLM and stores it as a document. Then, it uses this document’s embedding to search the vector store for retrieval.
Now, since we are searching based on a large relevant document, we expect the retrieval to perform significantly better than just searching with the user query alone.
In short, Think of HyDE as a smart translator. Instead of searching with your question directly, it first imagines what a perfect answer would look like, then searches for documents that match that imagined answer. Pretty neat, right?
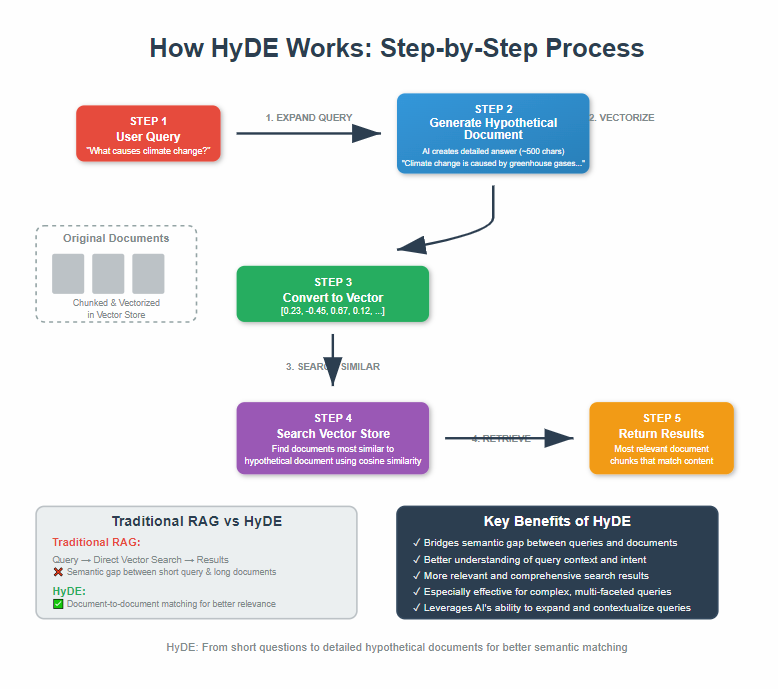
1. The Problem We’re Solving
Let me paint you a picture. You have a collection of documents and you ask: “What causes climate change?”
Traditional search systems take your short question and try to match it against long, detailed documents. It’s like trying to find a needle in a haystack when you’re not even sure what the needle looks like.
Here’s what usually happens:
- Your query: “What causes climate change?” (5 words)
- Document content: “Climate change results from increased greenhouse gas emissions, primarily carbon dioxide from fossil fuel combustion, deforestation, and industrial processes…” (detailed paragraph)
The semantic gap between your short question and the detailed answer creates mismatches. HyDE bridges this gap by first expanding your question into a hypothetical detailed answer, then searching for documents similar to that expanded answer.
2. How HyDE Works – The Magic Behind It
Let me break down HyDE’s three-step process:
- Query Expansion: Take your question and use an AI model to generate a detailed hypothetical document that would answer your question
- Embedding: Convert this hypothetical document into a vector (numerical representation)
- Retrieval: Search for real documents that are most similar to this hypothetical document
The beauty is that now you’re comparing document-to-document rather than question-to-document. Much better matches!
3. Setting Up Your Environment
Before we dive into the code, let’s get everything set up. I’ll assume you have Python and VS Code ready to go.
Before we start coding, let’s get all our tools ready. First, let’s install the packages we need:
bash
conda create -n rag2 python==3.12
conda activate rag2
pip install ipykernel
pip install langchain openai faiss-cpu python-dotenv tiktoken pypdf
Now let’s import everything:
python
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.vectorstores import FAISS
from langchain.prompts import PromptTemplate
from langchain.schema import Document
import textwrap
# Load your environment variables (make sure you have your OpenAI API key in a .env file)
load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv('OPENAI_API_KEY')
Quick note: Make sure you have a .env file with your OpenAI API key. It should look like this:
python
OPENAI_API_KEY=your_api_key_here
4. Loading and Processing Your Documents
Let’s start by loading a PDF document. For this example, I’ll use a climate change document, but you can use any PDF you want.
First, let me show you how to download the sample document:
Now let’s load and process the PDF
python
# Set the path to our document
document_path = "machinelearning.pdf"
# Load the PDF document
pdf_loader = PyPDFLoader(document_path)
raw_documents = pdf_loader.load()
print(f"Loaded {len(raw_documents)} pages from the PDF")
print(f"First page preview: {raw_documents[0].page_content[:200]}...")
python
Loaded 50 pages from the PDF
First page preview: Comprehensive Machine Learning Handbook
1. Overview and Definition of Machine Learning
Overview and Definition of Machine Learning plays a pivotal role in the broader ecosystem of artificial
intellige...
The PyPDFLoader reads each page as a separate document. But for better retrieval, we need to split the text into smaller, more manageable chunks.
5. Chunking Your Documents
Why do we chunk documents? Think of it this way: if you have a 10-page document and someone asks about a specific topic, you don’t want to return the entire document. You want to return just the relevant section.
Here’s how we’ll split our documents:
python
# Configure our text splitter
chunk_size = 500 # characters per chunk
chunk_overlap = 100 # overlap between chunks to maintain context
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
separators=["\n\n", "\n", " ", ""] # Try these separators in order
)
# Split the documents into chunks
document_chunks = text_splitter.split_documents(raw_documents)
print(f"Split {len(raw_documents)} pages into {len(document_chunks)} chunks")
print(f"Sample chunk: {document_chunks[0].page_content[:200]}...")
python
Split 50 pages into 228 chunks
Sample chunk: Comprehensive Machine Learning Handbook
1. Overview and Definition of Machine Learning
Overview and Definition of Machine Learning plays a pivotal role in the broader ecosystem of artificial
intellige...
The RecursiveCharacterTextSplitter is smart. It tries to split on paragraphs first, then sentences, then words, preserving context as much as possible.
6. Creating Your Vector Store
Now we need to convert our text chunks into vectors (numerical representations) and store them in a searchable format. Think of this as creating a smart index for your documents.
python
# Initialize OpenAI embeddings
embeddings_model = OpenAIEmbeddings()
# Create vector store using FAISS (Facebook AI Similarity Search)
vector_store = FAISS.from_documents(
documents=document_chunks,
embedding=embeddings_model
)
print(f"Created vector store with {len(document_chunks)} document chunks")
# Test the vector store with a simple search
test_query = "what is machine learning?"
similar_docs = vector_store.similarity_search(test_query, k=3)
print(f"Found {len(similar_docs)} similar documents for test query")
python
Created vector store with 228 document chunks
Found 3 similar documents for test query
FAISS is like a super-fast librarian that can instantly find the most similar documents to any query. It uses mathematical similarity (cosine similarity) to find matches.
7. Building the Core HyDE System
Now comes the exciting part – building our HyDE system! Let me break this down into digestible pieces.
First, let’s set up our language model for generating hypothetical documents:
python
# Initialize our language model
llm_model = ChatOpenAI(
temperature=0, # We want consistent, focused responses
model_name="gpt-4o-mini", # Good balance of quality and cost
max_tokens=1000
)
print("Language model initialized successfully")
python
Language model initialized successfully
Next, let’s create our prompt template for generating hypothetical documents:
python
# Create a prompt template for hypothetical document generation
hypothesis_prompt = PromptTemplate(
input_variables=["user_question", "target_length"],
template="""Given this question: '{user_question}'
Please write a detailed, informative document that directly answers this question.
The document should be comprehensive and approximately {target_length} characters long.
Write as if you're explaining this topic in a textbook or educational material.
Document:"""
)
print("Prompt template created")
python
Prompt template created
Now let’s put it all together in our HyDE retrieval function:
python
def create_hypothetical_document(question, target_length=500):
"""
Generate a hypothetical document that answers the given question
"""
# Create the chain using LCEL syntax
hypothesis_chain = hypothesis_prompt | llm_model
# Generate the hypothetical document
response = hypothesis_chain.invoke({
"user_question": question,
"target_length": target_length
})
return response.content
# Test our hypothetical document generation
test_question = "How is overfitting addressed in different types of ML algorithms?"
hypothetical_doc = create_hypothetical_document(test_question)
print("Generated hypothetical document:")
print("=" * 50)
print(hypothetical_doc)
python
Generated hypothetical document:
==================================================
Overfitting occurs when a machine learning model learns the noise in the training data rather than the underlying pattern, leading to poor generalization on unseen data. Different algorithms address overfitting through various techniques:
1. **Regularization**: Algorithms like linear regression and neural networks use L1 (Lasso) and L2 (Ridge) regularization to penalize large coefficients, discouraging overly complex models.
2. **Pruning**: Decision trees utilize pruning methods to remove branches that have little importance, simplifying the model.
3. **Ensemble Methods**: Techniques like bagging (e.g., Random Forests) and boosting (e.g., AdaBoost) combine multiple models to reduce variance and improve robustness.
4. **Cross-Validation**: This technique assesses model performance on different subsets of data, helping to identify overfitting during training.
5. **Early Stopping**: In iterative algorithms like gradient descent, training can be halted when performance on a validation set begins to degrade.
By employing these strategies, machine learning practitioners can enhance model generalization and mitigate the risks of overfitting.
This function takes your question and imagines what a perfect answer document would look like. The AI writes a detailed response as if it were creating educational content.
8. The Complete HyDE Retrieval Function
Now let’s create our main retrieval function that ties everything together:
python
def hyde_retrieve_documents(question, vector_store, k=3):
"""
Retrieve documents using the HyDE method
Args:
question: The user's question
vector_store: Our FAISS vector store
k: Number of documents to retrieve
Returns:
tuple: (retrieved_documents, hypothetical_document)
"""
# Step 1: Generate hypothetical document
print("Step 1: Generating hypothetical document...")
hypothetical_document = create_hypothetical_document(question)
# Step 2: Use hypothetical document to search vector store
print("Step 2: Searching for similar documents...")
retrieved_docs = vector_store.similarity_search(hypothetical_document, k=k)
return retrieved_docs, hypothetical_document
# Test our complete HyDE system
user_question = "How is overfitting addressed in different types of ML algorithms?"
results, hypothesis = hyde_retrieve_documents(user_question, vector_store)
print(f"\nRetrieved {len(results)} documents for question: '{user_question}'")
python
Step 1: Generating hypothetical document...
Step 2: Searching for similar documents...
Retrieved 3 documents for question: 'How is overfitting addressed in different types of ML algorithms?'
This is where the magic happens! Instead of searching with your original question, we search with the detailed hypothetical answer. This often leads to much better matches.
9. Analyzing Your Results
Let’s create a helper function to display our results in a readable format:
python
def display_results(question, retrieved_docs, hypothetical_doc):
"""
Display the results in a clean, readable format
"""
print("🤔 ORIGINAL QUESTION:")
print("-" * 50)
print(f"{question}\n")
print("💭 HYPOTHETICAL DOCUMENT:")
print("-" * 50)
# Wrap text to make it more readable
wrapped_hypothesis = textwrap.fill(hypothetical_doc, width=80)
print(f"{wrapped_hypothesis}\n")
print("📚 RETRIEVED DOCUMENTS:")
print("-" * 50)
for i, doc in enumerate(retrieved_docs, 1):
print(f"Document {i}:")
wrapped_content = textwrap.fill(doc.page_content, width=80)
print(f"{wrapped_content}")
print("-" * 30)
# Display our results
display_results(user_question, results, hypothesis)
python
🤔 ORIGINAL QUESTION:
--------------------------------------------------
How is overfitting addressed in different types of ML algorithms?
💭 HYPOTHETICAL DOCUMENT:
--------------------------------------------------
Overfitting occurs when a machine learning model learns the noise in the
training data rather than the underlying patterns, leading to poor
generalization on unseen data. Different algorithms address overfitting through
various techniques: 1. **Regularization**: Algorithms like linear regression
and neural networks use L1 (Lasso) and L2 (Ridge) regularization to penalize
large coefficients, discouraging overly complex models. 2. **Pruning**:
Decision trees utilize pruning methods to remove branches that have little
importance, simplifying the model. 3. **Ensemble Methods**: Techniques like
bagging (e.g., Random Forests) and boosting (e.g., AdaBoost) combine multiple
models to reduce variance and improve robustness. 4. **Cross-Validation**: This
technique assesses model performance on different subsets of data, helping to
identify overfitting during training. 5. **Early Stopping**: In iterative
algorithms like neural networks, training can be halted when performance on a
validation set begins to degrade. By employing these strategies, machine
learning practitioners can effectively mitigate overfitting and enhance model
performance.
📚 RETRIEVED DOCUMENTS:
--------------------------------------------------
Document 1:
Comprehensive Machine Learning Handbook 32. Overfitting and Regularization
Overfitting and Regularization plays a pivotal role in the broader ecosystem of
artificial intelligence. It addresses specific problems by enabling computers to
learn from data rather than relying on hard-coded rules. Over the past few
decades, researchers have refined mathematical frameworks and scalable computing
infrastructures, transforming overfitting and regularization from a theoretical
concept into a
------------------------------
Document 2:
practical engine that drives countless modern applications. At its core,
overfitting and regularization relies on statistical learning principles.
Algorithms iteratively uncover patterns, relationships, or decision boundaries
hidden within data. These patterns allow models to generalize to unseen
situations, providing predictions, classifications, or recommendations that
continuously improve
------------------------------
Document 3:
with additional feedback. The effectiveness of overfitting and regularization
hinges on high-quality data, rigorous evaluation, and appropriate hyperparameter
tuning. In industry, overfitting and regularization has catalyzed innovation
across sectors such as healthcare, finance, transportation, and entertainment.
While its benefits are immense, practitioners must address practical
------------------------------
This function helps you see the complete HyDE process: your original question, the hypothetical document that was generated, and the actual documents that were retrieved.
10. Comparing HyDE vs Traditional Search
Let’s see the difference between HyDE and traditional search side by side:
python
def compare_search_methods(question, vector_store, k=3):
"""
Compare HyDE retrieval with traditional direct search
"""
print("🔍 TRADITIONAL SEARCH (Direct Question):")
print("=" * 60)
traditional_results = vector_store.similarity_search(question, k=k)
for i, doc in enumerate(traditional_results, 1):
print(f"Result {i}: {textwrap.fill(doc.page_content[:200], width=70)}...")
print("-" * 40)
print("\n🎯 HYDE SEARCH (Via Hypothetical Document):")
print("=" * 60)
hyde_results, hypothesis = hyde_retrieve_documents(question, vector_store, k=k)
for i, doc in enumerate(hyde_results, 1):
print(f"Result {i}: {textwrap.fill(doc.page_content[:200], width=70)}...")
print("-" * 40)
# Compare the methods
comparison_question = "In what ways is machine learning applied to time series data?"
compare_search_methods(comparison_question, vector_store)
python
🔍 TRADITIONAL SEARCH (Direct Question):
============================================================
Result 1: drives countless modern applications. At its core, time series
forecasting relies on statistical learning principles. Algorithms
iteratively uncover patterns, relationships, or decision boundaries
hid...
----------------------------------------
Result 2: Comprehensive Machine Learning Handbook 41. Time Series Forecasting
Time Series Forecasting plays a pivotal role in the broader ecosystem
of artificial intelligence. It addresses specific problems by...
----------------------------------------
Result 3: evaluation, and appropriate hyperparameter tuning. In industry, time
series forecasting has catalyzed innovation across sectors such as
healthcare, finance, transportation, and entertainment. While it...
----------------------------------------
🎯 HYDE SEARCH (Via Hypothetical Document):
============================================================
Step 1: Generating hypothetical document...
Step 2: Searching for similar documents...
Result 1: drives countless modern applications. At its core, time series
forecasting relies on statistical learning principles. Algorithms
iteratively uncover patterns, relationships, or decision boundaries
hid...
----------------------------------------
Result 2: Comprehensive Machine Learning Handbook 41. Time Series Forecasting
Time Series Forecasting plays a pivotal role in the broader ecosystem
of artificial intelligence. It addresses specific problems by...
----------------------------------------
Result 3: engine that drives countless modern applications. At its core,
financial applications of ml relies on statistical learning
principles. Algorithms iteratively uncover patterns, relationships, or
decisi...
----------------------------------------
You’ll often see that HyDE retrieves more relevant and comprehensive documents because it’s matching against a detailed answer rather than a short question.
11. Advanced: Creating a Complete HyDE function
For more complex applications, you might want to wrap everything in a class. Here’s how you could structure it:
python
def answer_question_with_hyde(question, vector_store, provide_sources=True):
"""
Complete question-answering system using HyDE
"""
print(f"🤔 Question: {question}")
print("\n🔍 Searching for relevant information...")
# Retrieve documents using HyDE
retrieved_docs, hypothetical_doc = hyde_retrieve_documents(question, vector_store, k=3)
# Combine retrieved content
context = "\n\n".join([doc.page_content for doc in retrieved_docs])
# Create answer using the retrieved context
answer_prompt = PromptTemplate(
input_variables=["question", "context"],
template="""Based on the following context, answer the question comprehensively:
Context:
{context}
Question: {question}
Answer:"""
)
answer_chain = answer_prompt | llm_model
final_answer = answer_chain.invoke({
"question": question,
"context": context
})
print("\n💡 Answer:")
print("=" * 50)
print(textwrap.fill(final_answer.content, width=80))
if provide_sources:
print("\n📖 Sources:")
print("-" * 30)
for i, doc in enumerate(retrieved_docs, 1):
print(f"Source {i}: {textwrap.fill(doc.page_content[:150], width=70)}...")
print()
# Test the complete system
user_question = "How is overfitting addressed in different types of ML algorithms?"
answer_question_with_hyde(user_question, vector_store)
python
🤔 Question: How is overfitting addressed in different types of ML algorithms?
🔍 Searching for relevant information...
Step 1: Generating hypothetical document...
Step 2: Searching for similar documents...
💡 Answer:
==================================================
Overfitting is a common challenge in machine learning (ML) where a model learns
the training data too well, capturing noise and outliers rather than the
underlying distribution. This results in poor generalization to new, unseen
data. Different types of ML algorithms employ various strategies to address
overfitting, which can be broadly categorized into the following approaches: 1.
**Regularization Techniques**: - **L1 and L2 Regularization**: These
techniques add a penalty term to the loss function. L1 regularization (Lasso)
encourages sparsity in the model by penalizing the absolute size of
coefficients, while L2 regularization (Ridge) penalizes the square of the
coefficients. Both methods help to constrain the model complexity. -
**Dropout**: Commonly used in neural networks, dropout randomly sets a fraction
of the neurons to zero during training, which prevents the model from becoming
overly reliant on any single feature and encourages redundancy. 2. **Cross-
Validation**: - This technique involves partitioning the training data into
subsets, training the model on some subsets while validating it on others. This
helps in assessing the model's performance and ensures that it generalizes well
to unseen data. K-fold cross-validation is a popular method where the data is
divided into K subsets. 3. **Early Stopping**: - In iterative algorithms,
such as gradient descent used in neural networks, early stopping involves
monitoring the model's performance on a validation set and halting training when
performance begins to degrade. This prevents the model from fitting too closely
to the training data. 4. **Pruning**: - In decision trees and ensemble
methods like Random Forests, pruning involves removing sections of the tree that
provide little power in predicting target variables. This reduces the complexity
of the model and helps prevent overfitting. 5. **Ensemble Methods**: -
Techniques like bagging (e.g., Random Forests) and boosting (e.g., AdaBoost,
Gradient Boosting) combine multiple models to improve overall performance.
Bagging reduces variance by averaging predictions from multiple models, while
boosting focuses on correcting errors made by previous models, which can help
mitigate overfitting. 6. **Data Augmentation**: - Particularly in deep
learning, data augmentation involves creating modified versions of the training
data (e.g., rotating, flipping, or scaling images) to increase the diversity of
the training set. This helps the model learn more robust features and reduces
the risk of overfitting. 7. **Feature Selection**: - Reducing the number of
input features can help mitigate overfitting. Techniques such as recursive
feature elimination, feature importance ranking, or using domain knowledge to
select relevant features can simplify the model and enhance generalization. 8.
**Using Simpler Models**: - Sometimes, opting for a simpler model (e.g.,
linear regression instead of a complex neural network) can inherently reduce the
risk of overfitting. Simpler models have fewer parameters and are less likely to
capture noise in the data. 9. **Increasing Training Data**: - Providing more
training data can help the model learn the underlying patterns better and reduce
overfitting. This can be achieved through collecting more data or using
synthetic data generation techniques. In summary, addressing overfitting in
machine learning involves a combination of regularization techniques, model
evaluation strategies, and data management practices. By employing these
methods, practitioners can enhance the generalization capabilities of their
models, leading to better performance in real-world applications.
📖 Sources:
------------------------------
Source 1: Comprehensive Machine Learning Handbook 32. Overfitting and
Regularization Overfitting and Regularization plays a pivotal role in
the broader ecosyste...
Source 2: practical engine that drives countless modern applications. At its
core, overfitting and regularization relies on statistical learning
principles. Alg...
Source 3: with additional feedback. The effectiveness of overfitting and
regularization hinges on high-quality data, rigorous evaluation, and
appropriate hyperp...
This gives you a foundation to build upon for more complex applications.
12. Practical Tips and Best Practices
Here are some insights I’ve learned from working with HyDE:
Chunk Size Matters: The size of your document chunks affects retrieval quality. Too small and you lose context; too large and you get irrelevant information mixed in.
python
# Experiment with different chunk sizes
chunk_sizes = [300, 500, 800]
for size in chunk_sizes:
print(f"\nTesting chunk size: {size}")
# Create new text splitter with different size
test_splitter = RecursiveCharacterTextSplitter(
chunk_size=size,
chunk_overlap=100
)
test_chunks = test_splitter.split_documents(raw_documents)
print(f"Created {len(test_chunks)} chunks")
# You could create separate vector stores and compare results
Prompt Engineering: The way you ask the AI to generate hypothetical documents can significantly impact results.
python
# Try different prompt styles
alternative_prompt = PromptTemplate(
input_variables=["question"],
template="""You are an expert researcher. A student asks: '{question}'
Write a comprehensive paragraph that fully answers this question, including:
- The main answer
- Supporting details
- Context and background
- Relevant examples
Answer:"""
)
Free Course
Master Core Python — Your First Step into AI/ML
Build a strong Python foundation with hands-on exercises designed for aspiring Data Scientists and AI/ML Engineers.
Start Free Course →Trusted by 50,000+ learners
Related Course
Master Gen AI — Hands-On
Join 5,000+ students at edu.machinelearningplus.com
Explore Course

